Maskplace

Introduction
芯片布局方法分为两种,一种是传统的基于优化方法(classic optimization based approaches),第二种是基于学习的方法(learning-based approaches)
**基础优化:**一对向量(x,y)表示在 2D 上模块坐标值,布局目标函数为 min[WL(x,y)],服从 D(x,y)<=α(保证所以模块不重叠)。WL 为线长的估计函数,D 为密度的估计函数。
**传统的基于优化方法:**将布局问题公式转化成优化问题并且放松约束条件;
比如 DREAMPlace,方法:min[WL(x, y) + λD(x, y)],放松约束条件–> 导致后续手动细化和去掉重叠以至合法化。
**基于学习的方法:**RL 将布局作为顺序决策(sequential decision-making)问题解决
比如 Graph Placement 和 DeepPR 将网格(netlist)表示为超图(hypergraph)–>G = (V, E),V 是一组节点,每个节点是一个模块,E 是一组边,是连接模块之间的导线。
问题:超图(hypergraph)不能全面编码(encode)网表信息,比如 relative positions (offsets)被丢失了。没有这些引脚(pin)信息,线长是不准确的,但是全部编码会比较复杂。在 Graph placement 里面用 RL 放置 15% 的模块减少计算;DeepPR 中减少模块和芯片画布的大小(分辨率)。
MaskPlace 方法:将布局转化成像素级视觉表示学习问题(pixel-level visual representation learning)–>224 X 224
文中总结贡献:
1.芯片布局重新定义为一个学习视觉表示的问题 以全面描述芯片上数百万个电路模块
2.设计了一个新的策略网络,它可以在一个芯片画布上捕获和聚合全局和细微信息,最大化线长的回报,并确保有效的非重叠放置
3.MaskPlace优于最近的先进方法在24个公共芯片基准测试。
Preliminary and Notation
评估指标:HPWL
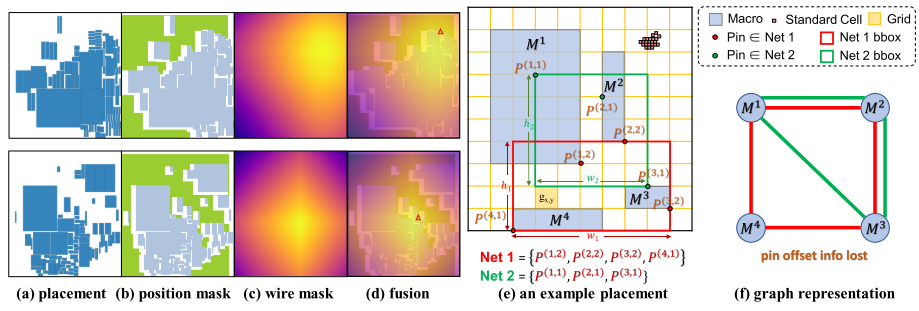
HPWL 计算 Step:
-
对于每个网络(net),找出连接在该网络上的所有引脚(pins)。
-
在这些引脚中,找到最小和最大的 x 坐标值,以及最小和最大的 y 坐标值。
-
使用这些坐标值来定义一个边界盒,该边界盒恰好覆盖所有的引脚。
-
计算这个边界盒的宽度(w)和高度(h),即最大和最小 x 坐标值的差以及最大和最小 y 坐标值的差。
-
对每个网络,半周长是边界盒的宽度和高度之和。
-
将所有网络的半周长加在一起,得到整个芯片的总 HPWL。
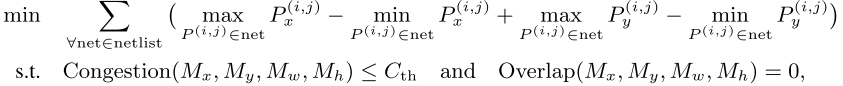
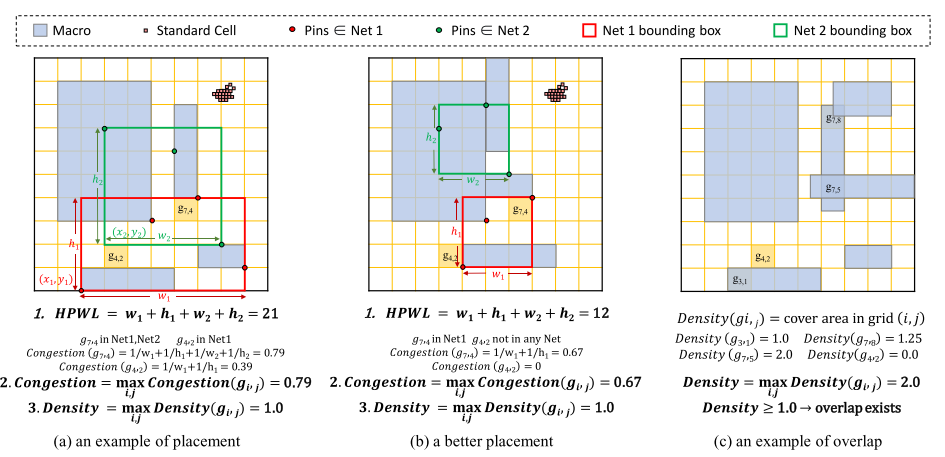
拥塞(Congestion)计算:
在 RUDY 方法中,每个网格单元需要累加覆盖该单元的所有网络边界盒的高度和宽度的倒数(1/h + 1/w),然后取所有网格单元中的最大值。
-
网络边界盒 1(Net 1 bounding box)覆盖 _g_7,4 ,其宽度 _w_1 和高度 ℎ1 的倒数之和为 1/w1 + 1/h1。
-
网络边界盒 2(Net 2 bounding box)也覆盖 _g_7,4,其宽度 _w_2 和高度 ℎ2 的倒数之和为 1/w2 + 1/h2。
-
为 g7,4 累加所有覆盖它的网络边界盒的宽度和高度的倒数。
-
拥塞值是所有网格单元中这个累加值的最大值。
密度(Density)计算:
密度是每个网格单元上模块覆盖区域比例的最大值。它是一个近似计算,旨在减少重叠并避免计算复杂度为 O(V2) 的约束的耗时计算。
以图8©为例,计算网格单元 g7,5 的密度值:
-
检查 g7,5 中叠加的模块数量。
-
如果 g7,5 被两个模块完全覆盖,那么这个网格单元的密度值为2.0。
Approach
模型框架(Model Architecture Overview):
布局过程可用马尔可夫决策过程(MDP)表示,训练一个策略 policy πθ(at|st),价值函数 Vφ(st),以先前 observations 和 actions 为输入,选择 actions 为输出。
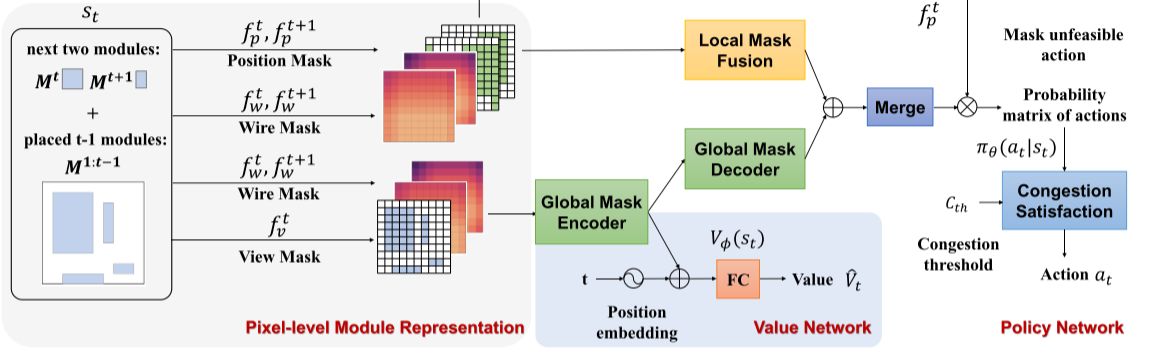
Position Mask(位置掩码):
224 X 224 画布网格,1 表示为模块可放置的可行位置(既绿色位置):
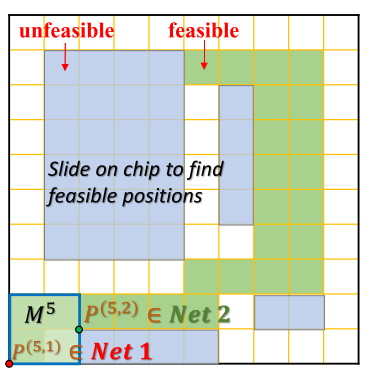
作用:保证模块之间没有重叠(即,满足重叠约束)并学习布局和线长之间的关系。
Wire Mask(线路编码):
一个连续的矩阵,用于表示如果我们在特定位置放置一个模块_Mt_,半周长线长(HPWL)会增加多少:
1.计算每个候选位置的 HPWL。这个过程本质上是 O(N2P) 复杂度的,其中 N 是候选位置的数量,P 是引脚的总数。
2.使用快速算法通过考虑引脚偏移、网络边界框以及 HPWL 度量的线性特性来降低计算复杂度。这意味着,通过调整网络边界框相对于引脚位置的关系,可以更快地计算出 HPWL。
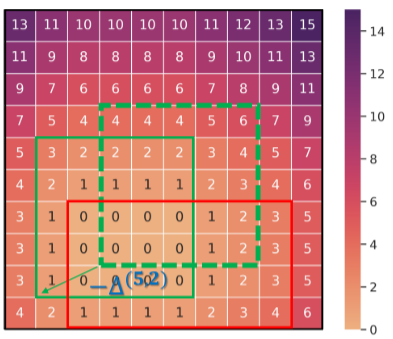
作用:目的是找到一个位置,使得增加的线长最小。
View Mask(视图掩码):
一种观察当前芯片布局的全局掩码,它是一个大小为 224×224224×224 的矩阵,其中每个元素的值为 0 或 1。在这个矩阵中,值为 “1” 表示相应的网格单元已被一个模块占据。 在处理芯片布局时,View Mask 考虑到了模块的真实大小,而不是假设所有模块都具有单位大小。这意味着,如果一个模块的尺寸是宽度 w 乘以高度 ℎ,那么它将占据画布上的[wN/W] X [hN/H]个网格单元。这里,W 和 H 表示画布的总宽度和高度,N 是画布网格单元的数量。
Learning Algorithm(学习算法):
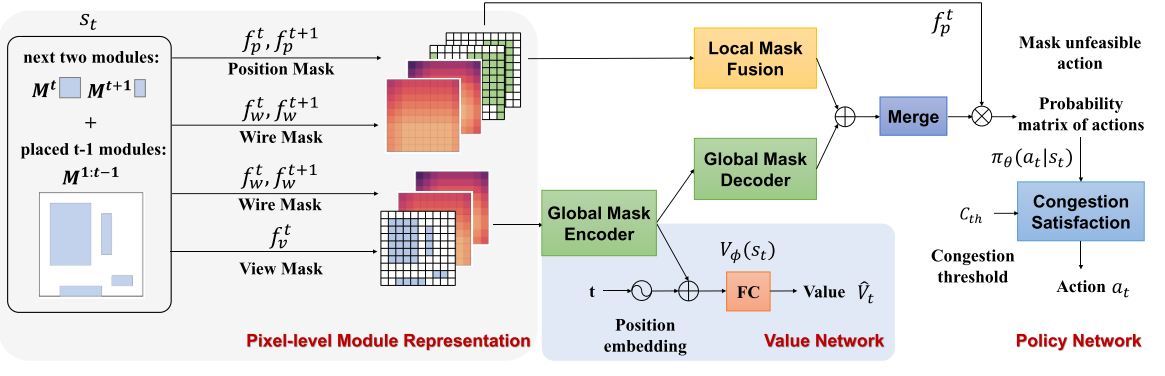
**1.应用掩码表示电路:**首先,我们应用上述掩码来表示整个电路,并将它们输入到下游网络。在图中,这些掩码包括位置掩码(Position Mask)、两个步骤后的线路掩码(Wire Mask),以及当前布局的视图掩码(View Mask)。
**2.全局特征编码器(Global Feature Encoder):**然后,全局特征编码器将当前布局的视图掩码和后续两个步骤的线路掩码嵌入到一个嵌入向量中。
**3.结合位置嵌入:**这个嵌入向量与第 t 个电路模块的位置嵌入在值网络中结合,通过全连接层生成一个标量来评估当前状态。
**4.全局掩码解码器(Global Mask Decoder):**接着,全局掩码解码器恢复一个大小为 N^2 的特征图,该特征图与策略网络中的不同位置掩码和线路掩码通过 1×1 的卷积融合,以避免局部信号扩散。
**5.策略网络(Policy Network):**策略网络预测一个大小为 N×N 的概率动作矩阵,指示下一个模块放置的位置。在采样动作之前,我们可以使用位置掩码来移除不可行的动作。
**6.拥塞满足模块(Congestion Satisfaction Block):**最后,拥塞满足模块应用拥塞阈值于概率矩阵上,以选择最终的动作。
Reinforcement Learning(强化学习):
采用了演员-评论家(actor-critic)架构和 PPO(Proximal Policy Optimization)算法来训练策略网络。
分割 N*N 个单元格。

**策略网络的目标函数(L_policy(θ)):**它是通过期望值形式来定义的,该函数试图最小化比率 r_t(θ)和优势函数 Â_t 的乘积。比率 r_t(θ)是当前策略和旧策略之间的比值,用于评估当前策略相对于旧策略的性能改进。优势函数 Â_t 是累积折现奖励 G_t 与估计值 V̂_t 的差,用于衡量特定行动的相对价值。
**累积折现奖励(G_t):**这是一个总和,计算从当前时刻起,未来的奖励值,并通过折扣因子 γ 降低远期奖励的重要性。
**价值网络的目标函数(L_value(φ)):**价值网络的目标是最小化实际累积奖励与估计累积奖励之间的差的平方。这个差异衡量了价值网络对于当前状态的估计准确性。
Reward:
Rt = HPWLt−1 −HPWLt
与 HPWL 增加相反。
Training and Testing:
Training 之前,根据网络数量,面积和已经放置固定的模块数量对电路模块排序,确定放置顺序。在训练中,我们通过忽略拥塞满意度块来更新每个时期的策略和值网络。当更新值网络时,我们停止了全局掩码编码器中的梯度反向传播,以避免对策略网络的影响。
Testing 时候针对每一个步骤 t:
**1.获取概率矩阵:**首先,从策略网络获取一个概率矩阵。
**2.采样动作:**从概率矩阵中采样一个放置动作 at。
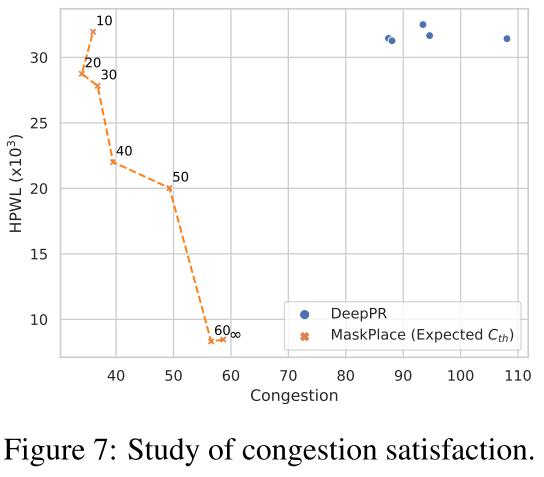
**3.拥堵满意度检查:**应用这个放置动作后,拥堵满意度模块会检查拥堵是否超过了一个阈值_Cth_。
**4.超过拥堵阈值:**如果拥堵超过了阈值:
-
均匀采样几个动作。
-
查找每个动作对应的线掩码中的值,并估算采取这些动作前的拥堵。
-
选择一个在线掩码中具有最小值且拥堵小于Cth 的动作。
**5.所有动作都超过拥堵阈值:**如果所有采样的动作都不能满足拥堵阈值_Cth_,那么选择拥堵最小的动作。
**6.进入下一步:**选择了动作后,移动到下一步。
Experiments
Optimization-based methods(优化算法):
NTUPlace3、RePlAce、DREAMPlace
Learning-based approaches(学习算法):
Graph Placement、DeepPR
Benchmark:
ISPD2005、IBM benchmark、Ariane RISC-V CPU design
Main Results:
所有宏的 HPWL 结果

Compare to Graph Representation:
与 Graph Placement 在 HPWL(半周线长), congestion(拥塞), density(密度), overlap area ratio(重叠面积比)这四个方向比较。

Routing Wirelength:
与 DeepPR 在 routing wirelength(布线线长)。

Standard Cells:
与 DeepPR、DREAMPlace 比较 macros(宏)和 standard cells(标准单元)的 HPWL。

Placement w/o real size:
考虑到 DeepPR 忽略了模块大小,我们在相同的设置中实现 MaskPlace。

Transferability:
在 adaptec1 训练得到的模型在其他数据集上效果,验证可移植性。

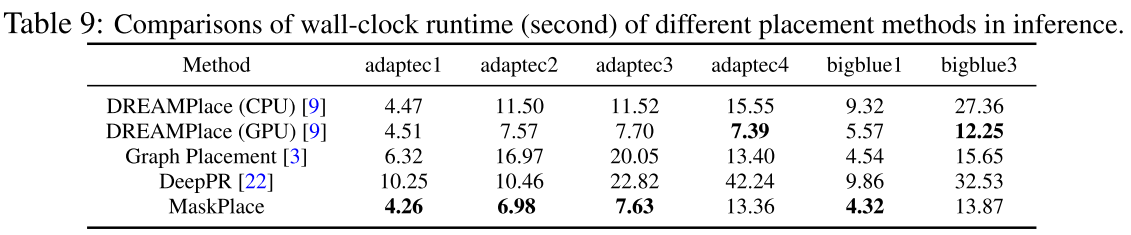
Efficiency:
不同方法下推理(inference)效率。
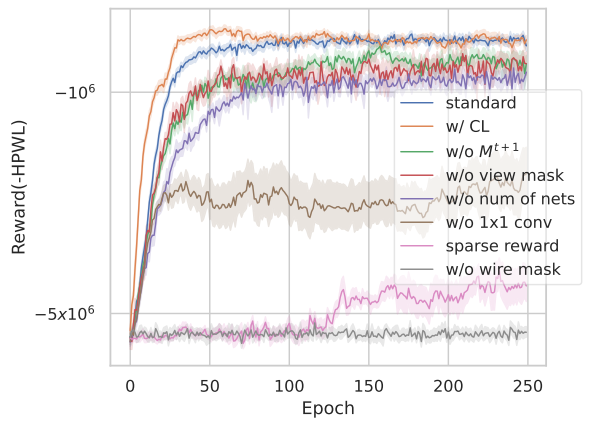
Ablation Study:
w/o 网络数量等一系列消融实验。
Congestion Satisfaction:
评估 congestion(拥塞)满意度。