DeepPR

Introduction
布局为芯片设计中最关键但最耗时的步骤之一,包括宏(SRAM…)和标准单元(逻辑与非门…)的布局。一个好布局带来芯片面积利用率,时序性能和布线能力,布局和布线时强相关的。布局的原则是 PPA --> Power(功耗), Performance(性能), Area(面积)。
对于芯片布局问题设计了一个 pipeline,input 输入为 hypergraph H = (V, E)代表的网表结构,V 指的是 node(单元 cells)集合,E 是电路组件连接的 edge(边)。
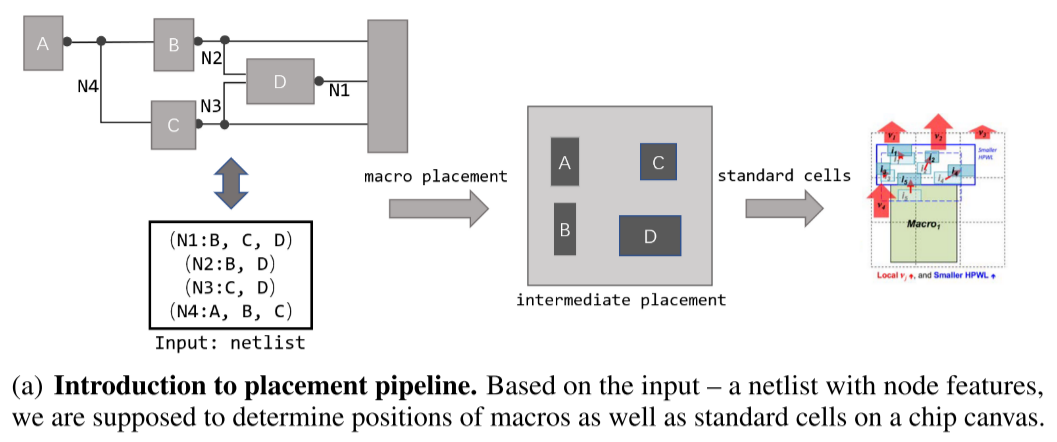
1.宏布局首先确定宏在芯片画布上的位置,然后大量的标准单元基于相邻的宏调整它们的位置,最后获得完整的布局解决方案。
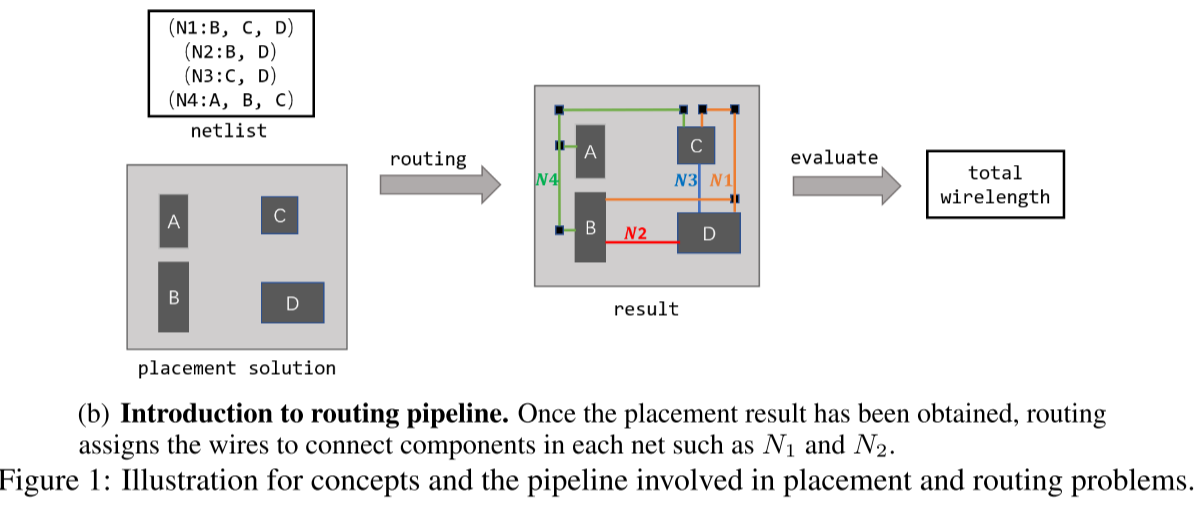
2.在不违反边约束前提下 实现总线长最小。
Method
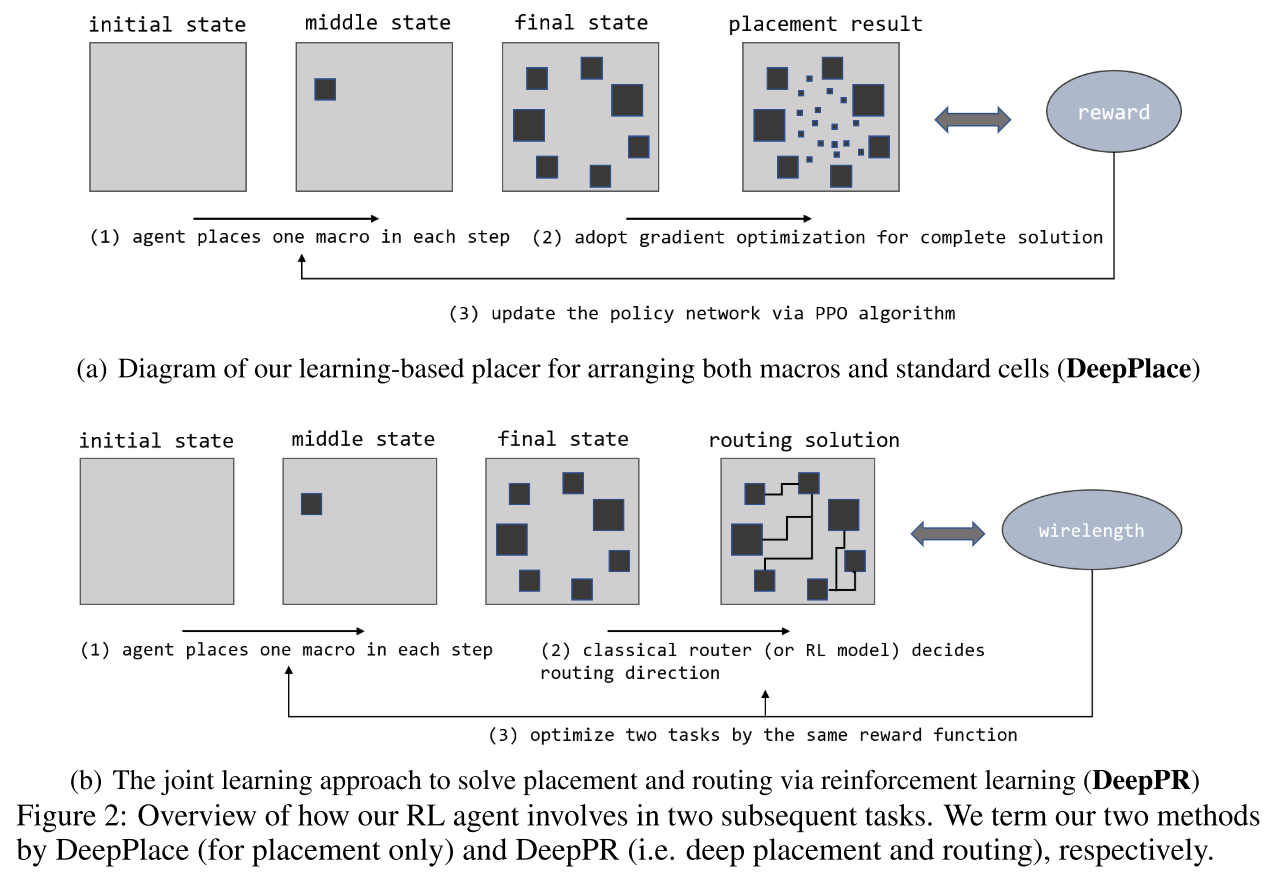
提出了一个叫 DeepPR 的两阶段布局算法,并且联合学习(joint learning)布局(placement)和布线(routing)任务:
-
第一阶段是用RL进行宏(macros)布局;
-
第二阶段是用基于梯度的优化放置器(gradient-based optimization placer)放置标准单元(cells);
文中给出了四个贡献:
-
提出一种端对端(end to end)的学习方法。
-
首次引入联邦学习同时解决布局和布线任务。
-
设计了一种新的策略方式,引入CNN和GNN提供两个视图,不是单个CNN或者GNN获得。
-
效果优于单独的布局或者单独的布线任务。
Related Work
Placement(布局)
Classical methods for Placement(经典放置方法):
Partitioning-based methods(分区方法):
分区方法是递归的将电路网表(netlist)和芯片布局进行划分,直到子列表获得最优解。
总结:分层结构执行速度快,更容易扩大到更大的电路网表,但因为是子结构独立解决最优解问题,导致牺牲质量。
Stochastic/hill-climbing methods(随机/爬山法方法):
总结:基于模拟退火办法,更灵活而且能更好找到全局最优解,缺点是随着电路网表规模增加,耗时很大。
Analytic solvers(解析求解器):
通常采用力导向方法和非线性优化器。
总结:二次方法计算效率高但性能相对较低,而非线性优化则更平滑地逼近成本函数,但复杂性更高。
例子:ePlace 、RePlAce
基于 GPU:
解析布局问题类似于训练神经网络,都涉及优化参数和最小化成本函数。
优点:通过深度学习工具包 PyTorch 实现了经过手工优化的关键运算符,相对于基于 CPU 的工具实现了超过 30 倍的加速。
例子:DREAMPlace
Learning-based methods for Placement(基于学习的方法布局):
1.端到端学习
以 Google 的 GraphPlace 为例,端到端的学习方法,用于宏单元的布局,将芯片布局建模为一个顺序决策问题。
每一步中,强化学习代理(RL agent)放置一个宏单元,使用目标指标作为奖励,直到执行最后一个动作。
图神经网络(GNN)被用于价值网络,以编码电路网表信息,而在策略网络中,反卷积层输出当前宏单元位置的掩码。
2.结合 RL 和启发式(SA)的方法
一种在强化学习和模拟退火(SA)之间循环的框架,其中强化学习模块调整电路组件之间的相对空间顺序,而模拟退火则基于强化学习初始化进一步探索解空间。
前者是一个具有与解析求解器相同目标函数的学习方法,而后者本质上是一个模拟退火求解器。
Routing(布线)
Classical & Learning-based methods for Routing(传统和学习方法对于布线):
Classical Routing:
多引脚网问题分解为一组双引脚连接问题。
每个引脚到引脚的布线问题通过经典的启发式方法解决,如 rip-up and reroute,力导向布线和区域式布线。
Learning-based methods for Routing:
使用深度强化学习(DQN)模型决定布线方向的行动,即在每一步选择向北、向南等。
提出了一种基于注意力的 REINFORCE 算法,用于选择布线顺序,并在确定布线顺序后使用模式布线器生成实际的布线。
应用遗传算法创建初始布线候选,并使用强化学习逐步修复设计规则违规。
Methodology
Problem Formulation:
首先对于宏布局问题 --> 没有重叠和线长最小 --> MDP
MDP:
State st:
全局图像 I --> 全局图像 I 是对芯片画布的抽象表示,类比为一个二进制图像,其中每个位置都可以被标记为 1(已被占用)或 0(空闲)。这里将芯片的布局问题比喻为一个棋盘游戏(例如,象棋或围棋),其中需要决定宏单元(棋子)的放置位置。因此,全局图像 I 是一个表示已占用和空闲位置的二进制图像,通过这种方式来描述宏单元的布局。
网表图 H --> 网表图 H 是一个包含所有已放置宏单元详细位置的网络图。在这个图中,每个宏单元都在芯片上有一个特定的位置。这个图反映了宏单元之间的相对关系,类似于棋盘游戏的规则,这些规则用来指导放置过程。因此,网表图 H 提供了对布局中宏单元位置的详细描述,是在强化学习中用来表示状态的一部分。
Action at:
动作空间包含在时间 t 时 n × n 画布上的可用位置,其中 n 表示网格的大小。选定当前宏单元的空闲位置(x,y)后,将 Ixy 设置为 1,并从可用列表中删除此位置。
Reward rt:
在每一轮结束时,奖励是最终解决方案的线长和路由拥塞的负加权和。权重是二者权衡,采用了随机网络蒸馏(RND)方法在每一个时间步计算奖励。
Policy:
邻近策略优化 PPO(Proximal Policy Optimization)
The Structure of Policy Network
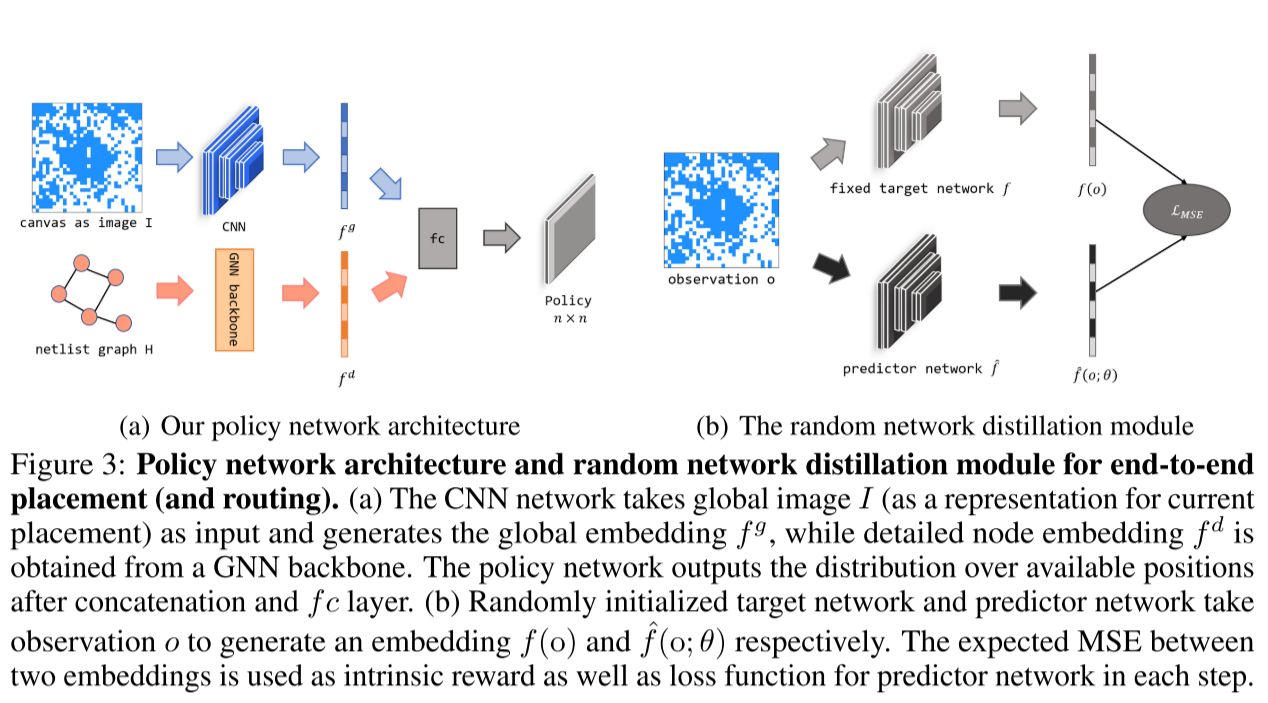
将当前状态表示为图像,用 CNN 和 GNN 进行全局详细信息 embed,生成 Action 的概率分布。
-
当前状态的图像表示:
- 由于解决宏单元布局问题与类似围棋等棋盘游戏的目标都是以顺序方式确定宏单元(棋子)的位置,因此将当前状态建模为大小为 n × n 的图像 I。在实验中,选择 n 从 {32, 64} 中进行。图像中的每个位置 (x, y) 上的 Ixy 被设为 1 表示先前的宏单元已经放置在这个位置上。这种图像表示提供了布局的整体概览,但可能会损失一些详细信息。
-
全局嵌入和详细节点嵌入的获取:
- 使用卷积神经网络(CNN)从图像 I 中获取全局嵌入。这一步的灵感来自围棋等游戏中 CNN 的成功应用。
- 使用图神经网络(GNN)为当前考虑的宏单元生成详细的节点嵌入。GNN 的作用是探索网表的物理意义,并将节点之间的连接性信息提炼为低维度的向量表示。
-
多视角嵌入模型:
- 将全局嵌入和节点嵌入通过连接操作进行融合。
- 将融合结果传递给一个全连接层,生成一个概率分布,用于描述在给定状态下执行不同动作的可能性。
- 该模型被设计成一个多视角嵌入模型,旨在综合探索全局和节点级别的信息,以更好地指导强化学习代理在每一步中作出决策。
Reward Design(奖励设计)
Extrinsic Reward Design(外在奖励设计)
定义了线长和拥塞的成本函数:
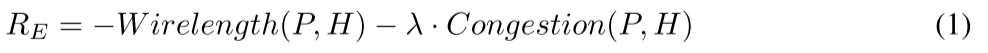
线长公式:
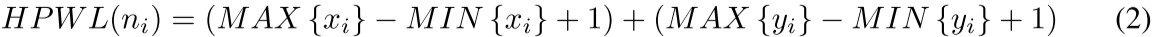
拥塞公式:
使用矩形均匀线密度(RUDY) 实验中设置拥塞阈值为 0.1
Intrinsic Reward Design(内在奖励设计)
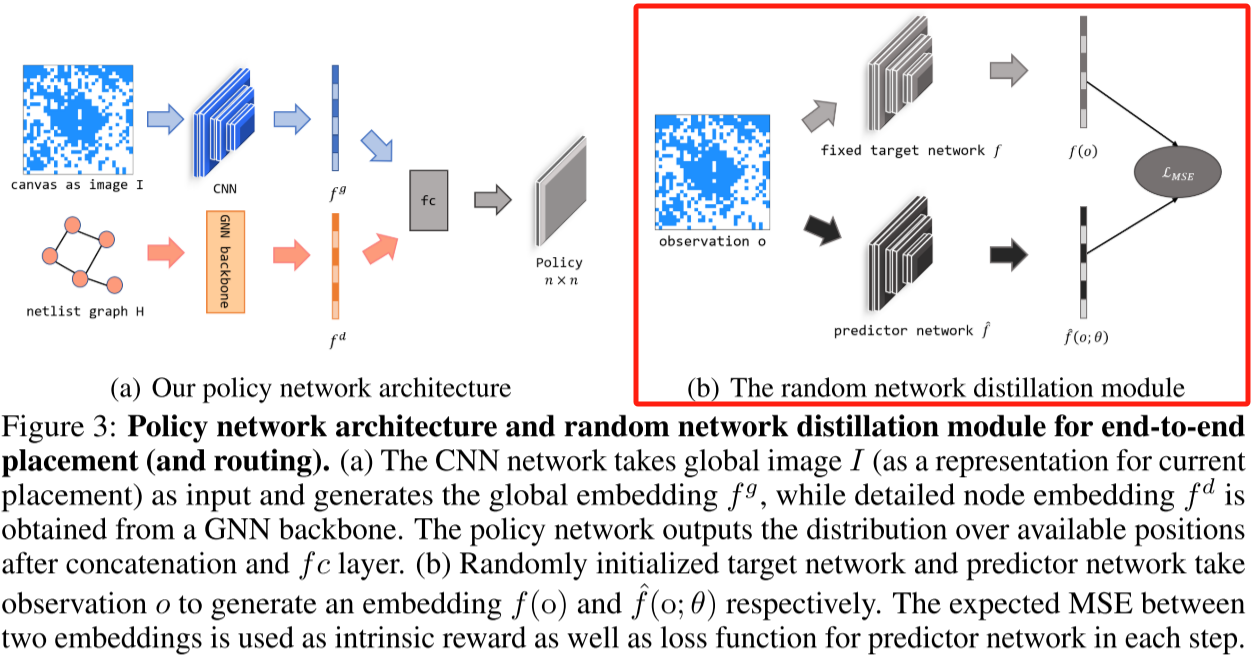
随机网络蒸馏(RND)涉及到两个网络,目标网络和预测网络。
题外话,介绍一下目标网络和预测网络作用:
1 | Answer from Chatgpt |
-
预测网络(Predictor Network):
- 预测网络通常是一个神经网络,它负责接收环境的输入,并输出对环境的某些方面的预测。
- 在强化学习中,预测网络的训练是为了使其能够准确地预测环境的一些方面。在文中的情境下,它可能学习预测布局状态的某些特征或属性。
-
目标网络(Target Network):
-
目标网络是另一个神经网络,它与预测网络相似,但在训练过程中不像预测网络那样频繁地更新权重。目标网络的参数是定期从预测网络中复制而来的,通常以较低的频率进行更新。
-
目标网络的目的是提供一个相对于预测网络的固定的、不容易变化的目标,以减缓训练中的不稳定性。这有助于确保目标的一致性,因为目标网络的参数在一段时间内保持不变。
在训练过程中,代理使用预测网络进行实际的动作选择和环境交互。然后,定期地,目标网络的参数被复制为预测网络的参数,以提供一个稳定的目标。这样的设置有助于稳定训练,减少因为网络参数的快速变化而导致的训练不稳定性。
-
Combination with Gradient-based Placement Optimization
标准单元放置。用 DREAMPlace 完成。
Joint Learning of Placement and Routing
依然是之前老生常谈 --> 我的理解是在布局之后紧跟就是布线 没有太新颖的做法
优点:
-
放置解决方案为布线代理提供了大量的训练数据,这比之前工作中使用的随机生成的数据更有优势,因为它能够更好地模拟真实场景下的数据分布。
-
布线为放置代理提供了一个直接的优化目标,从而减少了中间成本模型的需要,并减少了奖励信号中的偏差。(这里的偏差指的是单个布局或者单个布线任务代理相比较带来)
Experiments
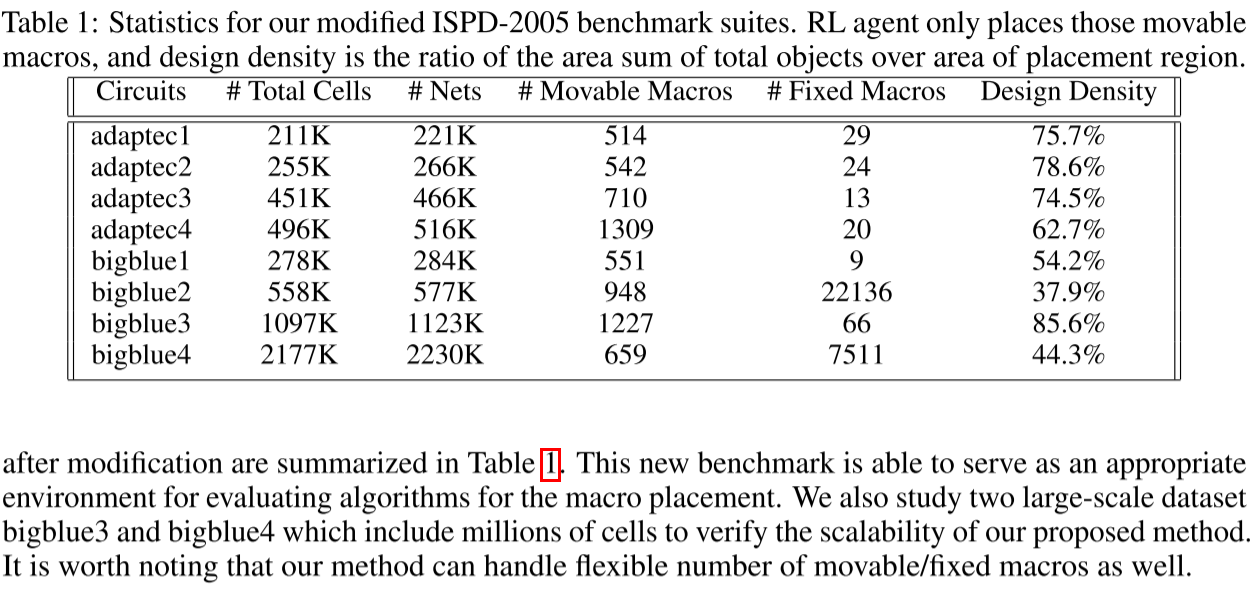
Benchmarks and Settings
Datasets : ISPD-2005
Policy : PPO
Backbone : GCN --> 一层 16 feature 一层 32 feature
Lr : 2.5 × 10−4
Pretraining
仅由宏(Macors)之间的连接组成网表训练策略(Policy)网络,为后续任务微调此预训练策略。
1 | Answer from Chatgpt |

我觉得说得很有道理
Results on Joint Macro/Standard cell Placement(布局结果)
Comparison of agents pre-trained on circuit adaptec1(预训练迭代次数对比):
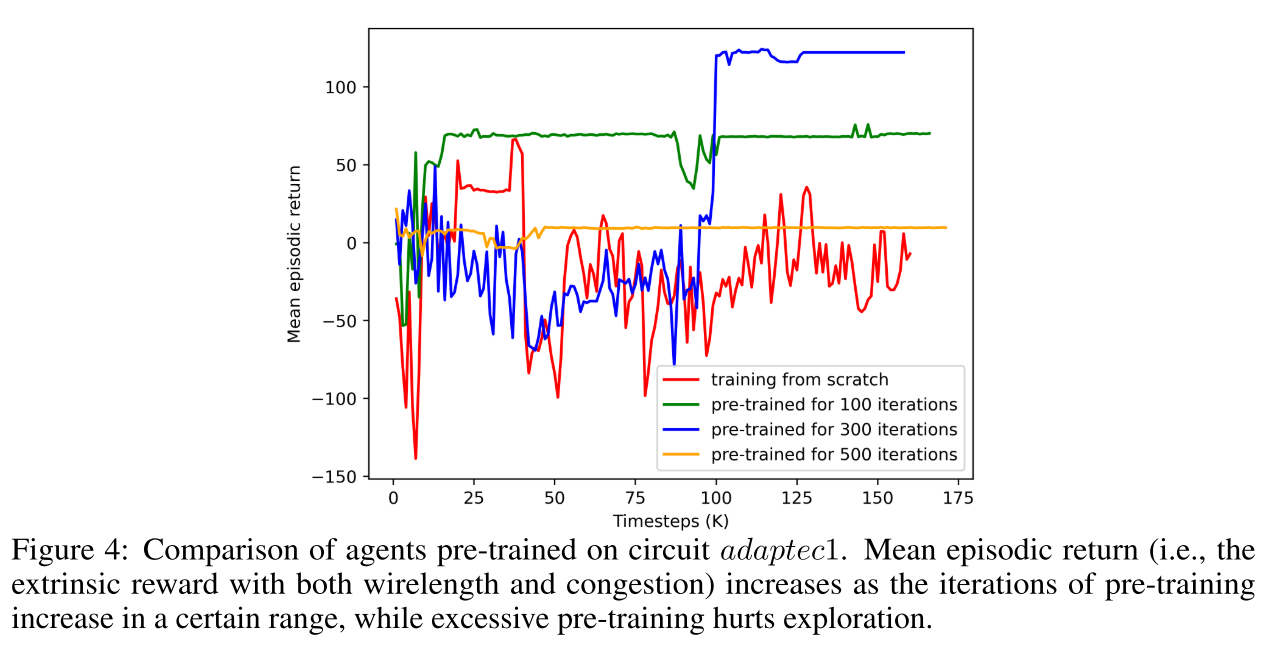
为 300 迭代时候效果最优。500 迭代可能过拟合了。
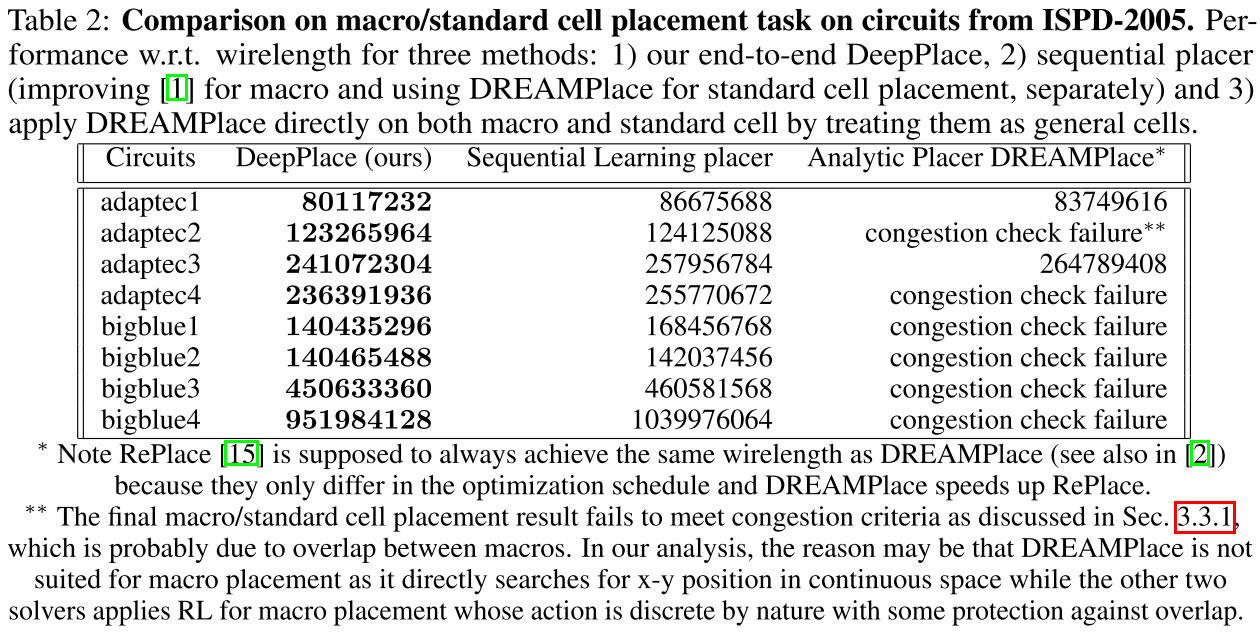
Comparison on macro/standard cell placement task on circuits from ISPD-2005(布局任务对比):
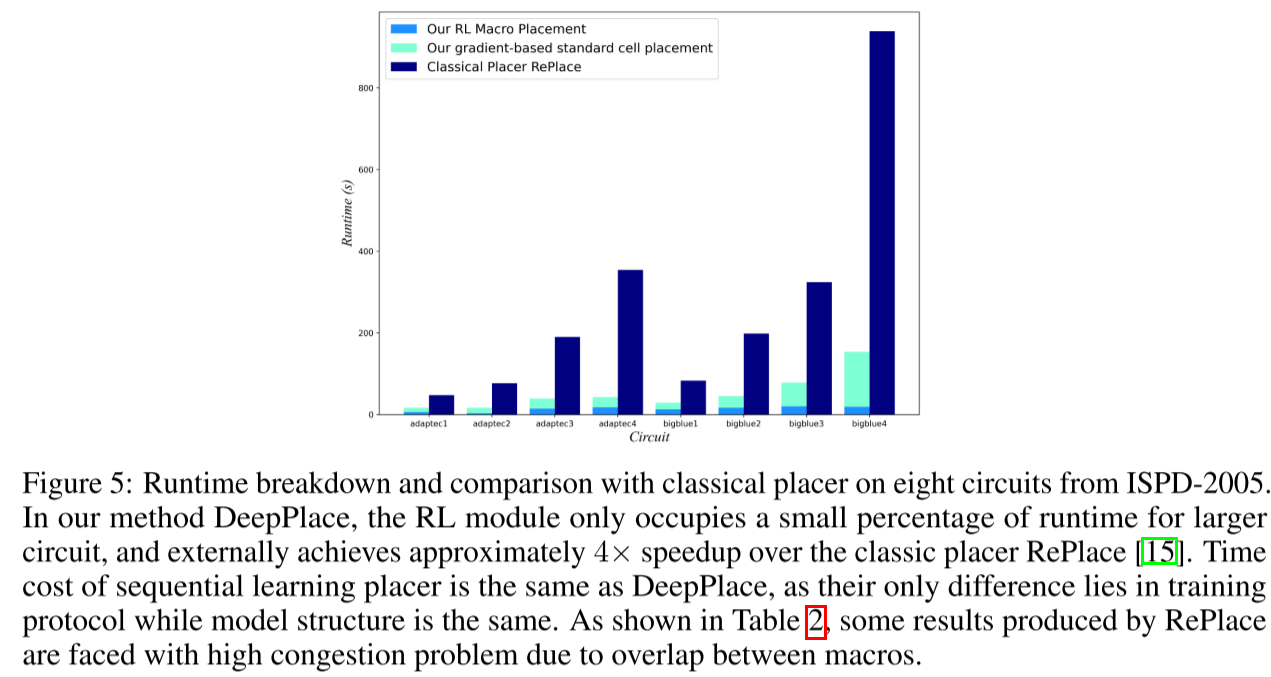
Runtime breakdown and comparison with classical placer on eight circuits from ISPD-2005(时间对比):
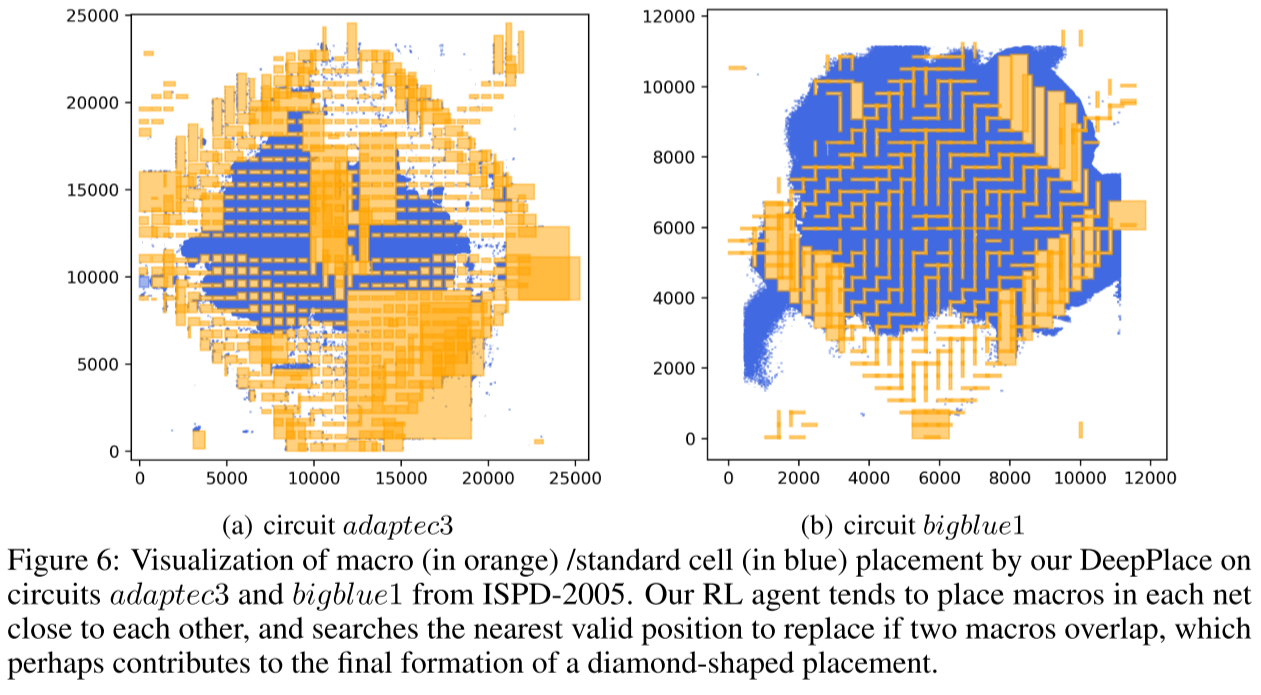
Visualization of macro (in orange) /standard cell (in blue) placement by our DeepPlace on circuits adaptec3 and bigblue1 from ISPD-2005(可视化结果):
Results on Joint Placement and Routing(布线布局联邦结果):
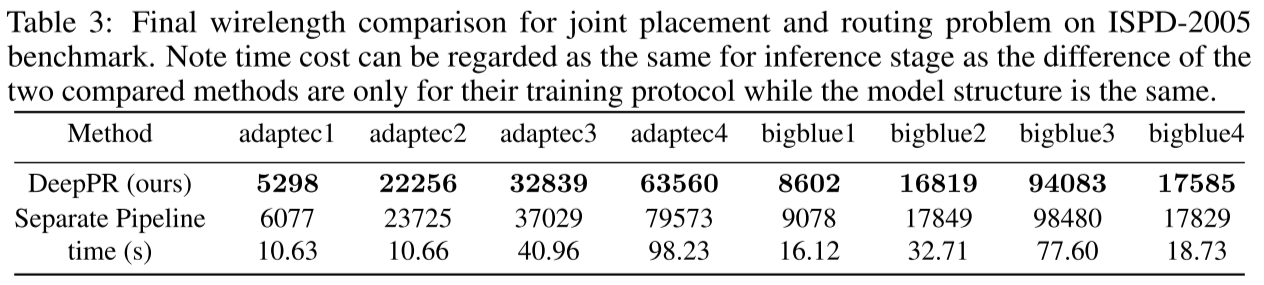
Final wirelength comparison for joint placement and routing problem on ISPD-2005 benchmark(HWPL 参数对比):
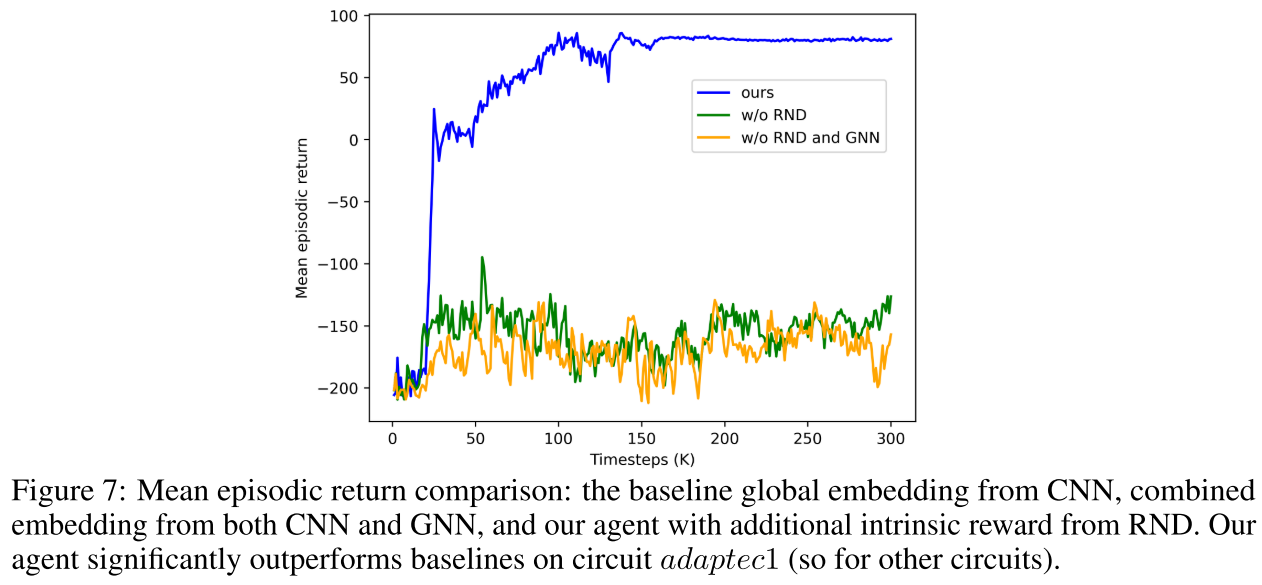
Ablation Study(消融实验):
三种消融实验对比 --> 证明随机网络蒸馏(RND)有效性