WireMask : Macro Placement by Wire-Mask-Guided Black-Box Optimization

Introduction
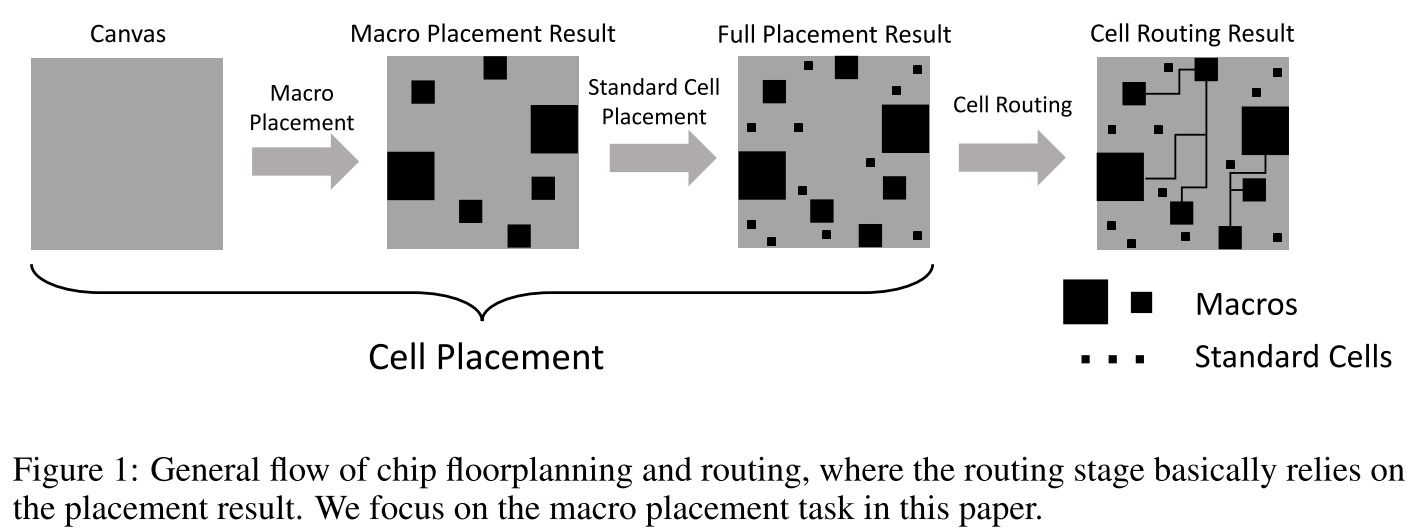
EDA 努力优化 PPA(power, performance, and area)指标,布局分为两个部分,宏布局和标准单元布局。其中宏布局通常使用启发式算法或深度学习方法,标准布局通常使用分析办法。放置所有单元后,执行布线任务。图 1 为一般 flow。文章作者更关注宏布局结果,因为影响更大。
早期的方法把宏布局任务比作矩形包装(rectangular packing)问题,其中有 sequence pair (SP) , B∗-tree , corner block list (CBL) ,等其他数据结构描表示,最后通过模拟退火(SA --> simulated annealing)办法解决。这种办法一般有较差可扩展性。
-
分析方法(Analytical methods):同时放置宏和标准单元,将任务化为数学规划问题,解决上述问题。但是此方法不能保证单元之间不重叠(non-overlapping)问题。
-
强化学习(RL): 将芯片布局图分为离散网格,将宏逐步放置到网格上,类似一个马尔可夫决策(MDP)过程。性能不错,但在实验中几百次就已经收敛了,没有充分利用搜索空间。
文中提出了一种新的 BBO 框架为布局任务,主要目标是最小化 HPWL 和避免重叠 overlapping。具体细节来说,用了线掩码(wire mask)通过将宏移动到每个网格,由此记录 HPWL 增量,将宏顺序调整到最近的最佳网络。这就是文中提出的 WireMask-BBO 框架核心。
WireMask-BBO 配备不同的 BBO 算法时候,比如随机算法(RS),贝叶斯优化(BO),进化算法(EA),显著优于其他算法(eg. 传统 BBO 算法,分析算法,RL 算法)
Analytical methods
Macro Placement
宏布局输入为 netlist H=(V,E) , V 表示所有单元信息(eg. 高度 宽度),E 表示多个单元在布线阶段的连接。每个宏在芯片画布上坐标表示为_(Xi , Yi)。_
具体参数指标:HPWL , Congestion , Density , Area。
Packing-based Methods
目的在于最小化宏的边界区域,导致更高的芯片面积利用率。每一个宏比作一个矩形,包装在一个指定的芯片画布。
解决方案的表示方法有 sequence pair (SP) , B∗-tree , corner block list (CBL) ,其中 SA 是扰动形成新的后代解以解决此类 BBO 问题。
divide-and-conquer idea(分而治之思想),标准单元用逻辑层次结构或者聚类算法成块,然后宏单元和混合标准单元块布局放置。最后,标准单元在块里面重新布局分配。虽然减小了问题规模,但是标准单元聚类成的块可能对最优解有阻碍或者影响。
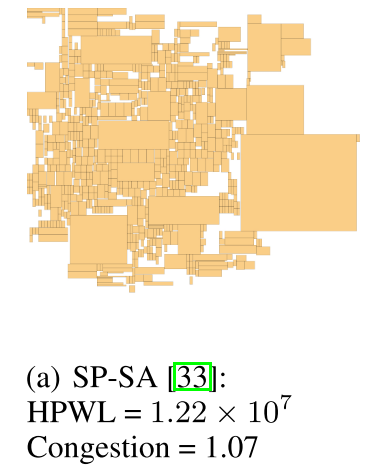
RL 决定选择扰动算子以及哪个宏应该被 SA 扰动,同时 CBL 建立 MDP,但并没有解决可扩展性差等本质问题。此外,在打包设置(就是宏单元聚类说法)下,每个宏的至少一个边缘必须连接到另一个宏或画布的边缘,这使得放置非常拥挤。图 2(a)为此布局 eg。拥挤的宏布局会限制标准布局空间,会导致布局性能不佳,eg 表 3。

Analytical Methods
分析方法同时放置宏单元和标准单元,将放置任务比作数学规划问题,eg:
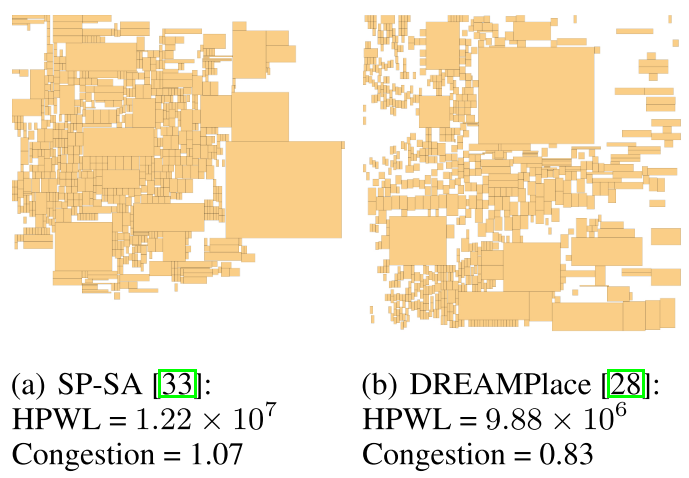
DREAMPlace ,将布局任务改写为 min WA(s,H)+ λ · Density(s,H),其中 WA 表示用于近似 HPWL 的平滑加权平均线长,Density 表示用于惩罚重叠的可微密度度量,λ 是权衡因子。用梯度下降等方法,完成高质量布局。图 2(b)所示。比图 2(a)效果更好,但是不能解决重叠 overlaps 问题。
Grid-based RL Methods
随着宏数量增加,Packing-based Methods 遇到可扩展性问题,而 Analytical Methods 遇到可重叠问题,为满足需求,有了 RL 方法。eg,
-
Graph placement:将芯片画布分为离散网络,每个宏分配离散坐标,并将布局问题公式化为MDP,agent决定每一步下一个宏的布局。直到最后一步,所有宏均被放置时,给出reward --> hpwl和congestion加权平均和。
-
DeepPR :在嵌入阶段集成了卷积和图神经网络,并引入了内在奖励来促进探索。然而,DeepPR带来了重叠。虽然PRNet将重叠区域作为惩罚纳入奖励函数,但在他们的实验中观察到的非重叠问题仍然存在。
-
MaskPlace:上述方法到最后一步都没有外在reward,为了解决此问题,MaskPlace介绍dense reward RL pipeline,有收集全局信息的view mask,为了避免不重叠的position mask,用于评估当前宏放置结果的wire mask。wire mask提供了一个即时奖励,计算当前宏放置后HPWL增加。此方法可以在合理的时间给出一个高质量非重叠的布局结果。eg 图2©为结果,该示例优于图2(a)和2(b)中所示的填充和分析方法生成的示例。仅在几百次评估后就收敛,这意味着巨大的布局搜索空间可能仍然没有得到充分利用。

Proposed Framework WireMask-BBO
Wire-Mask-Guided Problem Formulation
Solution representation
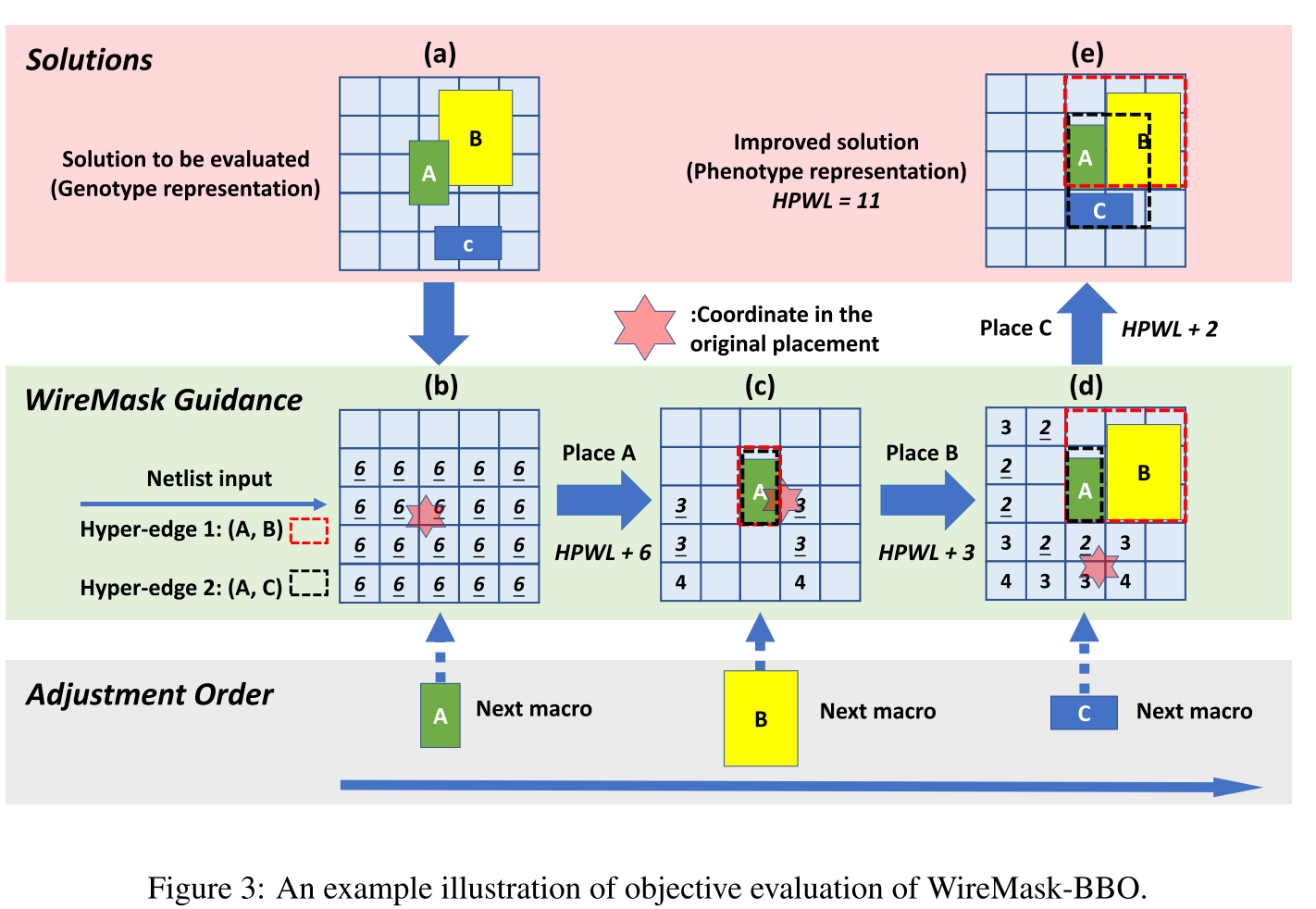
宏的坐标表示,_(Xi , Yi)。_eg 图 3 中的布局任务,存在三个宏 A、B 和 C,因此解决方案 s 由(x1,y1,x2,y2,x3,y3)表示。
Objective evaluation
算法步骤:
-
算法首先根据与每个宏块连接的单元格的总面积来对宏块进行排序。
-
将芯片画布划分为 m×m 的网格,并且初始化一个解决方案(基因型表示),其中每个宏块的位置都对应于网格中的一点。
-
然后,算法按照排序后的顺序依次调整每个宏块的位置。
-
对于每个要调整的宏块,首先计算一个 Wire Mask Wi,该掩膜记录了将宏移动到每个候选网格时 HPWL 的增量。
-
算法选择增量最小的网格,并将宏块移动到这个网格中。如果有多个这样的网格,则选择距离原始位置最近的网格。
-
在调整所有宏块位置之后,得到一个改进的解决方案(表现型表示)以及其对应的 HPWL 值。
演示步骤 eg:
-
原始解决方案(图 3a):展示了三个宏块 A、B 和 C 在画布上的原始位置。这个布局被视为基因型表示,是算法的输入。
-
线掩膜指导(图 3b):算法首先计算了一个线掩膜,它基于 netlist 输入,并且显示了将宏块 A 放置在每个网格中会增加多少 HPWL。图中每个网格的数字表示将宏块 A 放置在那里的 HPWL 增量。
-
调整宏块 A 的位置(图 3c):选择了最小化 HPWL 增量的网格,并将宏块 A 移动到该位置。这里显示的数字 3 是 HPWL 的增量最小值,意味着将 A 放在这个位置是局部最优的。
-
调整宏块 B 的位置(图 3d):在宏块 A 的位置调整之后,算法计算将宏块 B 放置在不同网格上的 HPWL 增量,并再次选择一个最佳的网格来放置宏块 B。
-
调整宏块 C 的位置并得到最终改进解决方案(图 3e):继续这个过程,对宏块 C 进行位置调整。图中显示了所有宏块调整后的最终位置,并计算了最终的 HPWL 值为 11,这是算法输出的改进解决方案,也就是表现型表示。
Black-Box Optimization
上述公式化问题可以通过任何 BBO 算法解决,实验中使用了随机算法(RS),贝叶斯优化(BO),进化算法(EA),其中 RS 为历史最佳值。
对 BO 来说,采用有效的 TuRBO 方法来直接优化连续坐标(x1,y1,…,xk,yk),导致 2k 的维度,其中 k 是宏的数量。
对 EA 来说:选择简单的(1+1)-EA,它只保留一个解,并通过变异迭代地改进它。
这三种方法均能超过以往的算法。
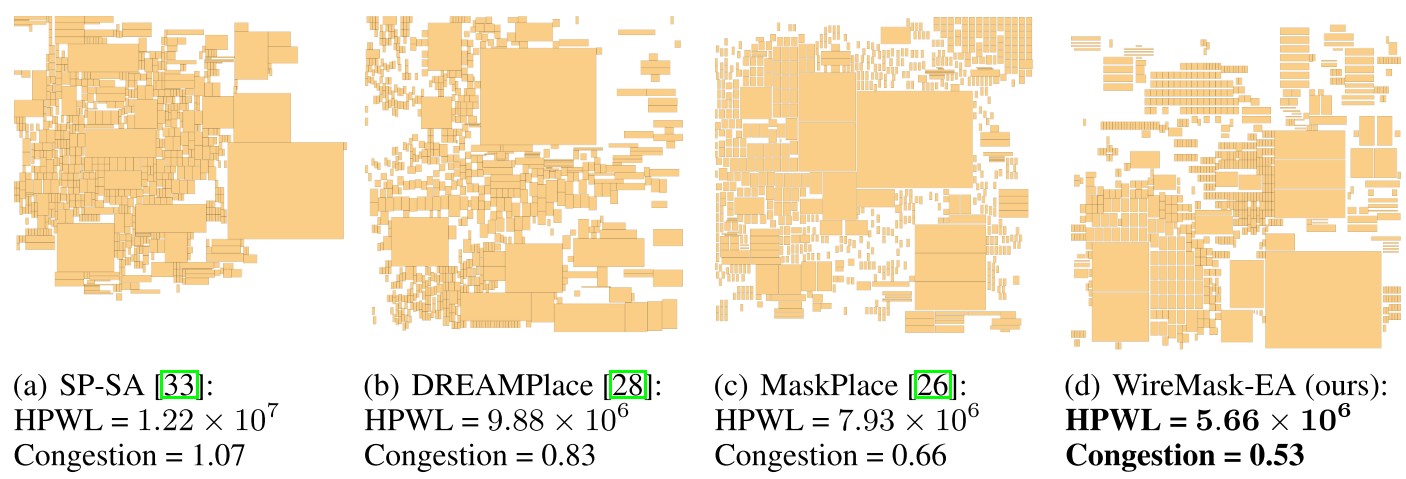
WireMask-BBO --> 基于网格离散化和 Wire Mask 引导的贪婪算法,有效地生成非重叠的高质量布局,解决了基于包装的方法的可扩展性差的问题以及分析方法的重叠问题。黑盒优化的使用增强了探索能力,使 WireMask-BBO 能够超越最先进的基于 RL 的方法 MaskPlace。eg 图 2。
Experiments
数据集是 ISPD05,里面缺少了 bigblue2 和 bigblue4(bigblue 2,它有超过 20000 个宏和 30000 个与宏相关的超边,评估花费超过一个小时)。
Main results
HPWL 指标:
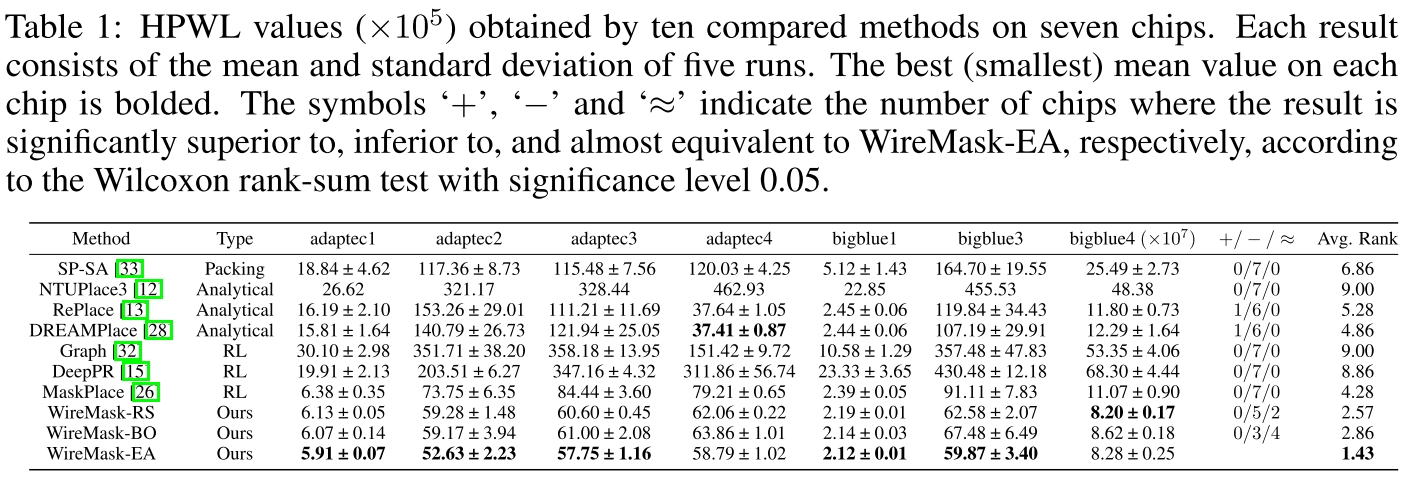
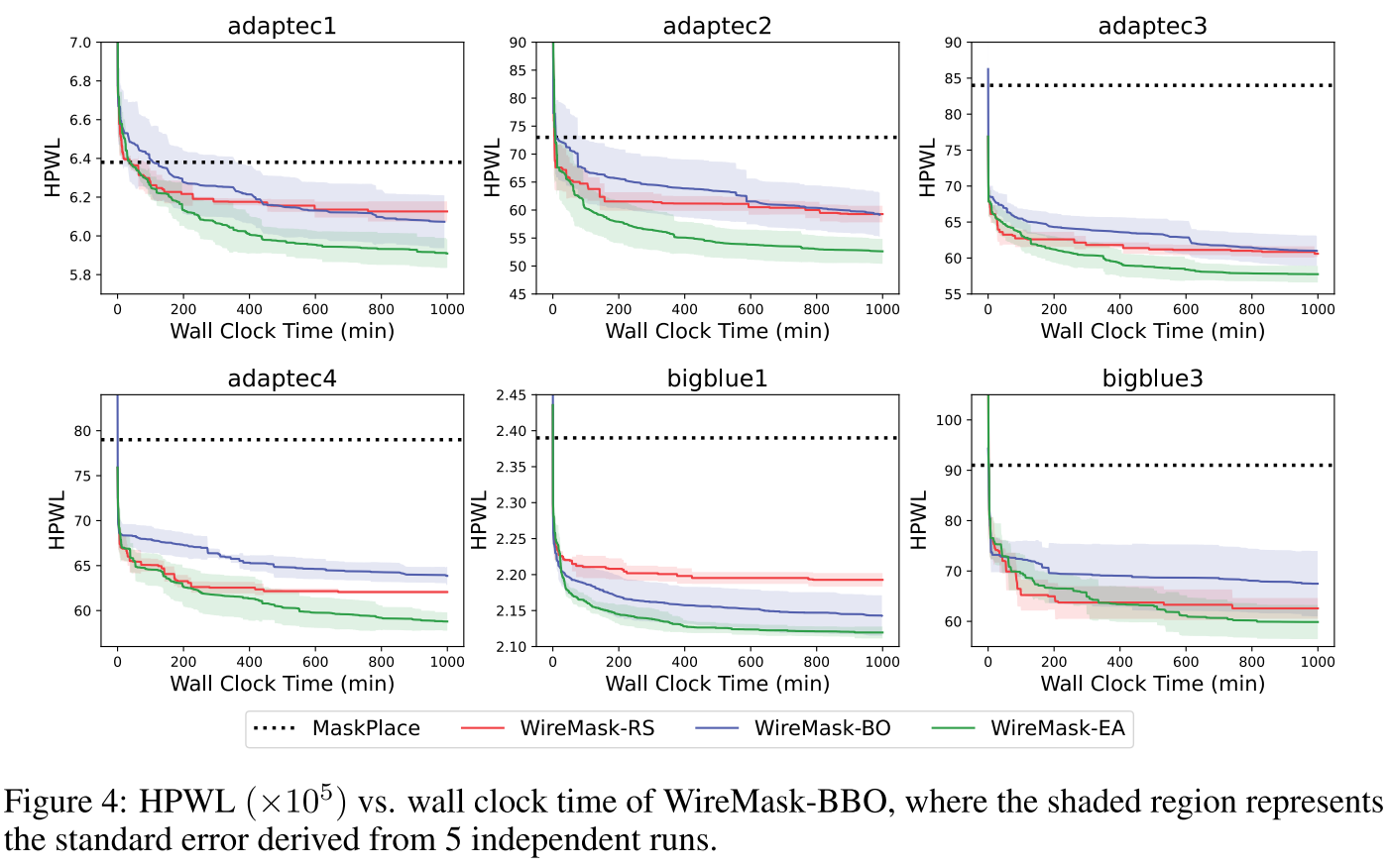
WireMask-EA 为最优。
Running time analysis
WireMask-BBO 的任何变体都比 MaskPlace 表现最好,MaskPlace 在之前的方法中排名最高。
Performance on congestion metric
评估放置拥塞与 MaskPlace 和 SP-SA 比较。Base --> WireMask-EA 的拥塞设置为 1.00 来规范化拥塞值。eg 表 2。

Full placement results
比较 PRNet and DREAMPlace。eg 表 3。

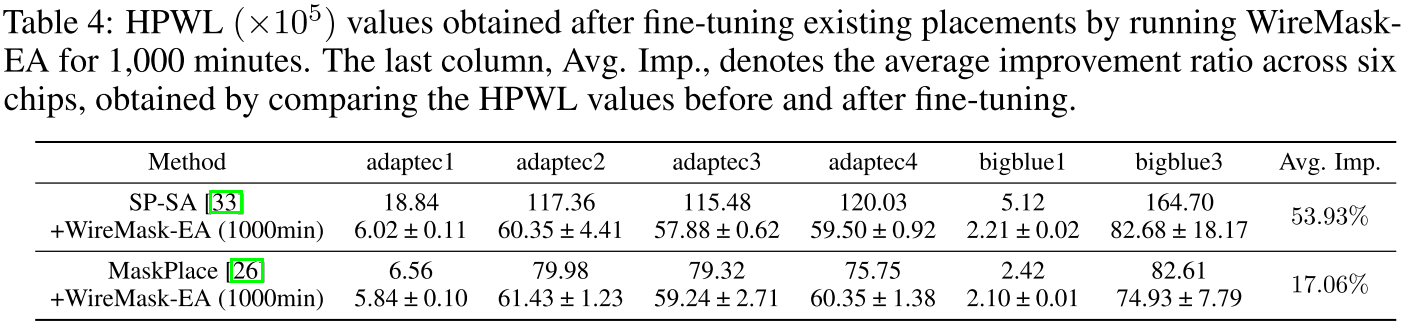
Fine-tuning results
微调结果 。通过 WireMask-EA 微调 1,000 分钟前后 SP-SA 和 MaskPlace 的 HPWL 结果,平均改善率分别为 53.93% 和 17.06% --> eg 表 4。
Additional results
提出了一个后本地搜索过程(post local search procedure),以进一步提高最终的安置结果。并且包括与两个并发的先进方法 --> ChiPFormer & Autoclave,WireMask-EA 仍然保持了上级性能。