AutoDMP: Automated DREAMPlace-based Macro Placement

Introduction
宏对芯片布局产生较大影响,需要优先关注宏布局。设计目标有线长、功率和面积。讲布局问题分解为先放置宏单元,再放置标准单元。
混合布局方法,比两阶段布局更有前景。宏单元合法化(macro legalization)对混合布局来说有挑战性 --> 特别是宏单元紧密封装。所以需要新的有效和高效设计空间探索技术。
我们提出了一个宏布局方案 AutoDMP --> 基于自动 DREAMPlace(Automated DREAMPlace-based) 贡献如下:
-
搜索宏布局设计空间 --> 多目标贝叶斯优化(multi-objective Bayesian optimization)。调整GPU加速的混合布局放置,比针对PPA(power-performance-area)来探索设计空间。
-
提出一个两级的PPA评估方案来管理空间复杂度。首先使用代理模型对宏布局快速评估,仅将判定为Pareto最优(在多目标优化问题中,如果一个解在所有目标上都不比其他任何解差,那么这个解就被认为是Pareto最优的),将此布局方案送入更为复杂且精确的商业EDA工具中进行进一步评估。–> 减少昂贵EDA工具评估的设计方案数量,提高flow效率。
-
增强混合布局方案,开源分析DREAMPlace,减少合法化问题扩展设计空间,增强潜在PPA实现。
-
在NVIDIA DGX Station工作站上测试,测试结果与商业工具媲美。在开源TILOS数据上展示线长和时序结果。
Related work
-
模拟退火算法:
- 宏布局 --> 数据表示:序列对(sequence pairs)、角块列表(corner block lists)、树状结构(tree-like structures)、B 树(B-trees)
- 退火算法非常灵活,但是可扩展性差,快速(fast)和多级(multilevel)方法提出来提高可扩展性。
-
分区方法:
-
CircuitTraining:
- 得到了商业解决的 PPA 方案。
- Training 和 Finetune 过程比较耗时。
-
SOTA:同时布局
- 宏和标准单元放在一起,结合宏单元处理方法,eg. shredding,shifting,re-legalization
- 全局分析布局,线长优化(wirelength optimization)和非重叠约束(non-overlapping constraints)视为非线性优化问题。
- 在同时布局中,合法化(确保组件不重叠)是一个基本挑战,尤其是在现代异构系统芯片(SoC)设计中,宏占据了大部分芯片面积。有时,只能通过严重恶化线长来找到一个可行的布局。
-
顺序布局
- 尝试性地放置宏和标准单元:可能会将标准单元聚集成软块以提高速度,或者丢弃标准单元的布局,仅优化宏的布局。
- 固定宏后进行标准单元布局:使用已建立的方法执行标准单元布局。
- 在工业界广泛使用。
Preliminaries
DREAMPlace
DREAMPlace --> SOTA for 全局布局 ; ABCDPlace --> 传统顺序布局
DREAMPlace 将全局布局问题化为密度约束下的线长最小化:
-
E是网表
-
(x,y)是单元位置
-
WL项是净电荷的HPWL平滑版本
-
平滑密度函数lambda是静电系统势能
DREAMPlace 无法保证合法放置宏单元,此外,放置参数(placer parameters)和随机种子(random seeding)严重影响优化收敛和最终目标值,导致脆弱和不可预测的结果。
tree-structured Parzen estimator (TPE)
EDA 工具和参数调优中,一种顺序模型 --> tree-structured Parzen estimator (TPE 树结构 Parzen 优化器)
-
核心概念:TPE 通过构建“好”(G)和“差”(P)样本的分布来工作。样本根据其在目标空间中相对于当前 Pareto 前沿的位置被分类。
-
工作流程:算法首先收集多个随机样本,然后基于这些样本构建内部分布。这些分布遵循一种称为 Parzen 窗口的非参数多变量密度估计模型。
-
决策机制:好的分布 G 用于绘制许多候选样本,TPE 选择期望改进最大的那个,即选择 G(x)/P(x)值最大的样本。
-
优点:TPE 的一个重要优势是它能够处理离散和连续值参数。
-
扩展
- 多目标 TPE 将单目标 TPE 扩展到可以处理多目标空间的情况,采用多维分割。 --> 这种扩展允许 TPE 同时优化多个目标,如在 EDA 工具中同时优化性能、功耗和面积等不同的设计目标。
AutoDMP farmework
框架依赖于 high-level 的 PPA 指标,指导对宏布局空间探索。代理是在 ABCDPlace 对 DREAMPlace 同步布局执行合法化和详细布局之后提取的。
提出了新的 DREAMPlace 方法和参数,解决宏布局合法化问题,并扩大设计空间,提出两阶段方法用多目标贝叶斯优化探索布局空间,提高解决方案质量。
PPA Proxies
线长(Wirelength)、密度(Cell Density)、拥塞(Congestion)
Wirelength
指标使用最小斯坦纳树(RSMT) --> 使用 FLUTE 算法(快速启发式算法)计算各个网络 RSMT
Cell Density
影响:过高的单元密度会导致布线区域的拥挤。
DREAMPlace的密度优化方法
-
电场类比:DREAMPlace采用基于ePlace的密度公式,通过模拟单元为带正电荷的粒子在电场中的行为来优化系统的势能。单元被吸引到势能稳定点,对应于均匀的单元密度。
-
优化目标:优化的目标是使得芯片布局区域内的电荷溢出(电场强度过高的区域)低于某个阈值(T=0.07),这时认为达到了优化目标。
-
布局区域划分:芯片布局区域被划分为矩形区块(bins),每个区块的单元密度是通过计算该区块内所有单元的重叠面积之和来确定的。目标单元密度(dtarget)是优化过程中尝试达到的均匀密度值。
处理标准单元和宏的不同
最终布局目的使整个芯片布局达到与目标单元密度相等的均匀密度。由于实际利用率低于目标密度,需要添加填充物来达到目标密度,即通过填补标准单元之间的间隙而不是在所有区块上过度分布单元来实现。
Congestion
RUDY 计算
DREAMPlace Extensions
扩展 DREAMPlace --> 提高放置估计和质量
RUDY with Macro Blockages
RUDY 估计提供了一个二维利用率图,在放置后轻松快速计算。 DREAMPlace 中的 RUDY 没有考虑宏的阻塞,这些阻塞可能迫使连线绕过宏的边界,影响布线路径和拥塞。解决这个问题:
-
通过使用布线层数和最小金属间距,可以计算出每个网格单元(gcell)的水平和垂直布线供应量 s(g)H/V 。
-
对每个宏_m_,定义一个单位布线需求_α_(m)H/V=o(m)H/V/a(m),其中_a_(m)是宏的面积,o(m)是宏阻塞使用的布线供应。
$$
\mathrm{RUDY}(g){H/V}=\frac{\sum{e\in E}\frac{\mathrm{OA}(e,g)}{\mathrm{BBOX}(e){V/H}}}{s(g){H/V}-\sum_{m\in M}\alpha(m)_{H/V}\mathrm{OA}(m,g)}
$$
-
OA_表示网格单元_g_与宏_m_或连线_e_的边界框_BBOX(e)的重叠面积。
RISA Net Weights
线长代理是 RSMT,不是 HPWL,在全局和详细布局中使用加权线长,增加与 RSMT 布线相关性。
Gradient Descent Optimizer
提高收敛 --> 采用了不同梯度计算
$$
\mathrm{lr}{init}=\frac{|z{0}-z_{1}|{2}}{|\nabla f(z{1})-\nabla f(z_{0})|{2}},\quad z{1}=z_{0}-\mathrm{lr}{0}\cdot\nabla f(z{0})
$$
Heuristics Simplification
简化启发式算法 --> 删除多个启发式算法(多个算法导致放置不稳定性)
优化过程中保持简单的一阶密度惩罚。停止条件简化为检查目标和密度溢出(density overflow)变化。
Macro Orientation Refinement
DREAMPlace 中宏单元和标准单元布局时候方向是固定。在详细放置结束后,单元格根据放置行方向旋转。对标准单元是没有影响,但是宏单元方向显著影响线长(宏单元旋转影响最大位移)。
采用贪心算法改进:宏单元在四个方向上依次旋转,每个宏在一次迭代中只考虑一次,减少就改进,增量低于 0.02% 停止。
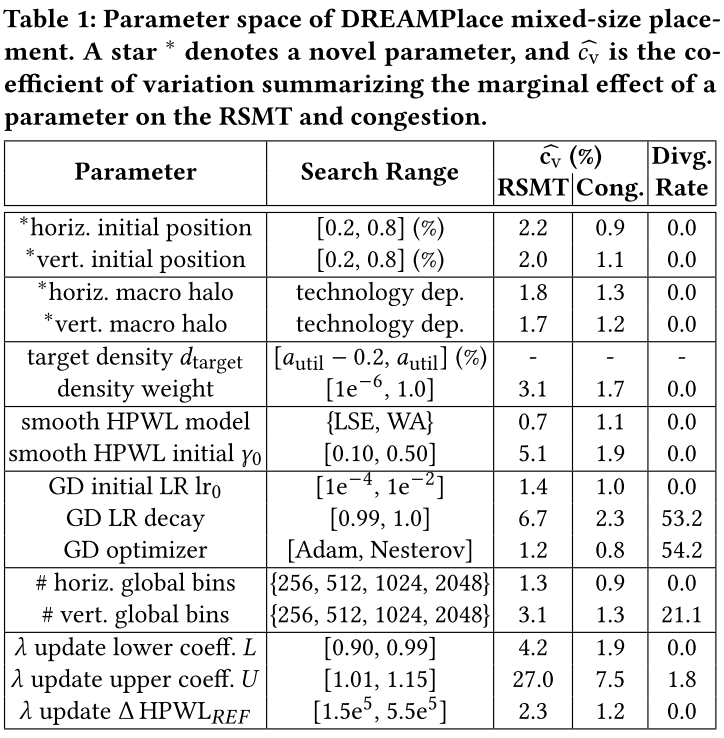
Parameter Space
列出 DREAMPlace 16 个参数 eg.表 1:
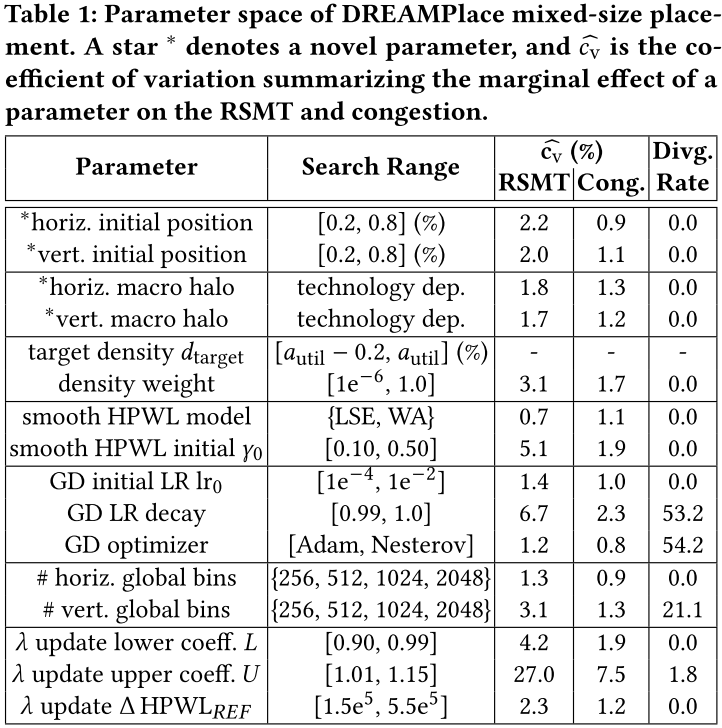
在此基础上,提出了新的参数,解决合法化问题。
Default DREAMPlace Parameters
调整学习率(LR)、衰减、梯度下降优化器。
Initial Locations
开始放置时,宏单元和标准单元集中在一个位置,最大限度减少线长。随着密度项拉格朗日乘子逐渐增加,单元扩散,在全局布局结束时候达到最小势能配置。 DREAMPlace 最初将单元格和宏的所有初始位置设置在平面图的中心,eg.图 1:
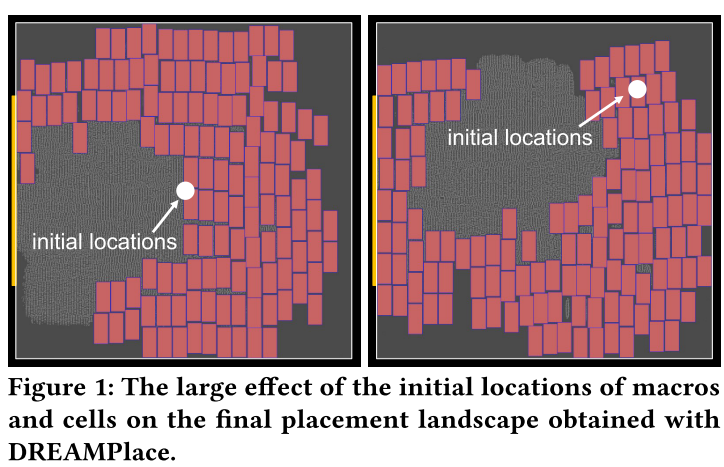
调整初始位置显著影响最终排列形状。宏单元是第一个展开,梯度通常也是最显著且稳定,决定标准单元布局位置。
为了扩大布局多样性,引入了两个参数来设置初始单元的位置作为布局的宽度和高度的百分比。遵循高斯分布的噪声也被添加到初始位置以避免零初始梯度。
Macro Halos
对 DREAMPlace 中宏单元合法性问题解决。 在宏单元边界加光晕,保留足够空间。eg.图 2:

Parameters’ Effect
进行了敏感性分析,证明选择表 1 参数。eg.表 1:
Design Space Exploration
MOTPE
MOTPE(多目标优化应用) 搜索多个目标的 Pareto 最优解的方法,能够直接且有效地生成具有多重权衡(线长、密度和拥塞)的 Pareto 前沿。
Two-level Approach
两级方法:
-
使用 MOTPE(多目标贝叶斯优化)进行贝叶斯优化,通过调整 DREAMPlace 参数在大规模的布局空间进行搜索,评估解决方案在高级指标(RSMT、密度和拥塞)上的表现。
-
在采样过程结束时,从 Pareto 前沿选择最有前途的候选解,并在 EDA 工具内进行更高级的评估,包括线长、时序和功率等指标。如果中间的 PPA 质量非常不满意,可以提前终止 EDA 流程。
eg.图 3: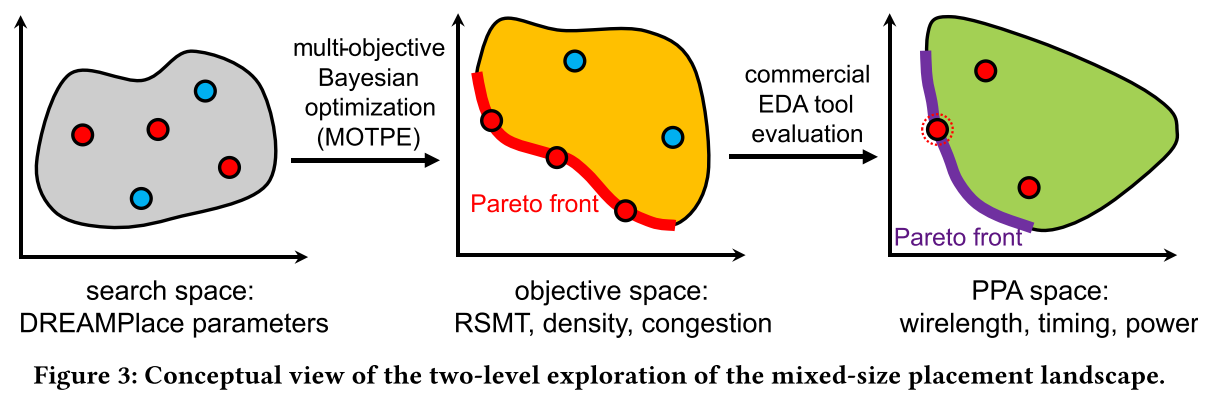
概念上显示了两级探索方法。- 左边的区域表示通过DREAMPlace参数调整进行搜索的空间。
- 中间的黄色区域表示利用MOTPE得到的Pareto前沿。
- 右边的绿色区域表示在商业EDA工具中使用PPA指标(线长、时序、功率)对解决方案进行评估的空间。
Pareto 最优点的选择:
-
问题:搜索过程可能产生许多 Pareto 最优点。然而,由于资源共享限制(如服务器和工具许可证),在 EDA 工具中评估许多点是不切实际的。
-
解决方案:使用 k 均值聚类方法来减少候选解的数量,聚类 3D Pareto 点。接近目标代理空间的点对应于外观相似的布局。
eg.图 4: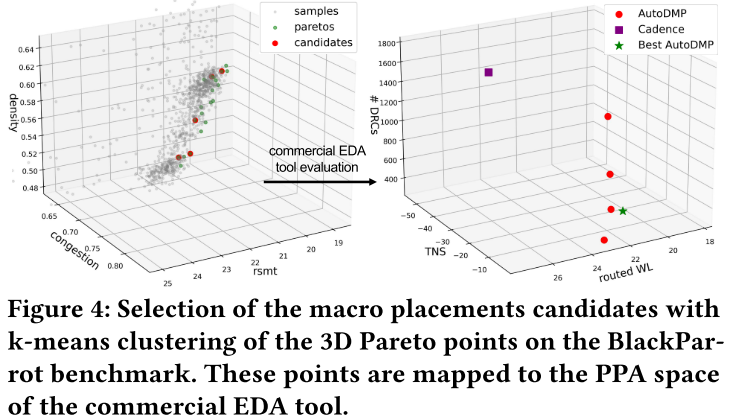
展示了评估过程中的一个基准测试的宏布局候选选择过程:- 图中灰色点表示采样点,绿色点表示Pareto点,红色点表示通过k均值聚类选择的候选解。
- 右侧的图展示了这些点在PPA空间的映射,其中不同颜色的方块表示不同工具或方法得到的结果。
Infrastructure
Flow show eg.图 5:

Experiments
AutoDMP 框架是在 DREAMPlace 和 ABCDPlace 之上开发的。Flow 流程遵循 TILOS 宏布局流程。实现 Cadence Innovus 21.15 完成。RTL 设计使用 Cadence Genus 21.14 生成。
数据集(benchmark)采用 TILOS 开源数据集。混合布局数据集有 Ariane --> RISC-V CPU,MemPool Group 和 BlackParrot 设计。
此外,使用开源工艺设计工具包 NanGate 45nm 匹配 TILOS 报告的当前状态。
References1 – Linux-capable RISC-V multicore
References2 – TILOS-AI-Institute
Benchmark Results
布线优化结果报告
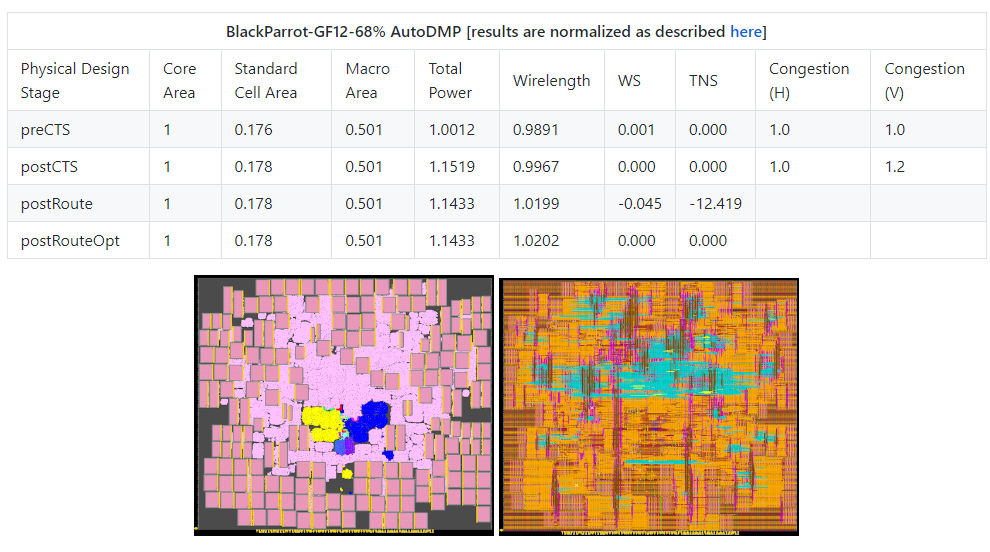
布线优化后的结果报告,主要检查时序(timing)、设计规则检查违规(design rule check --> DRC)、功耗(Power)和布线长度(routed wirelength)。虽然是报告了 PPA(功耗,性能,面积)之一,但其他两个参数也令人满意。eg.图 4:
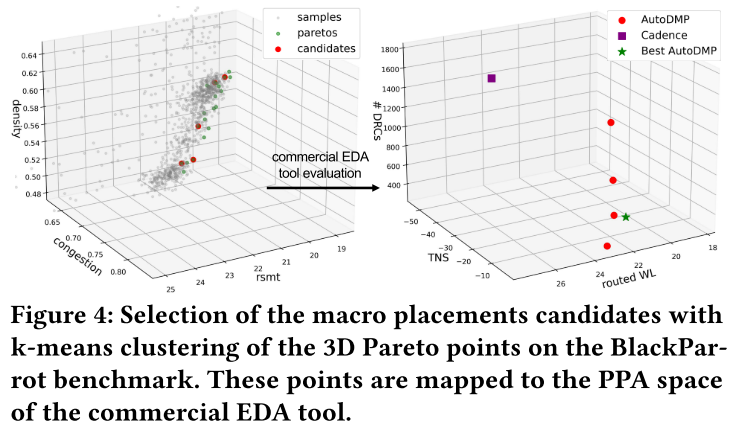
显示 BlackParrot 的宏放置都具有一致的质量。
AutoDMP 算法可行性验证
表 2 展示了使用 AutoDMP 放置和使用参考 TILOS 流程得到的放置的 PPA 结果。TILOS 流程采用了 Innovus 以顺序 full placement 方式。eg.表 2:
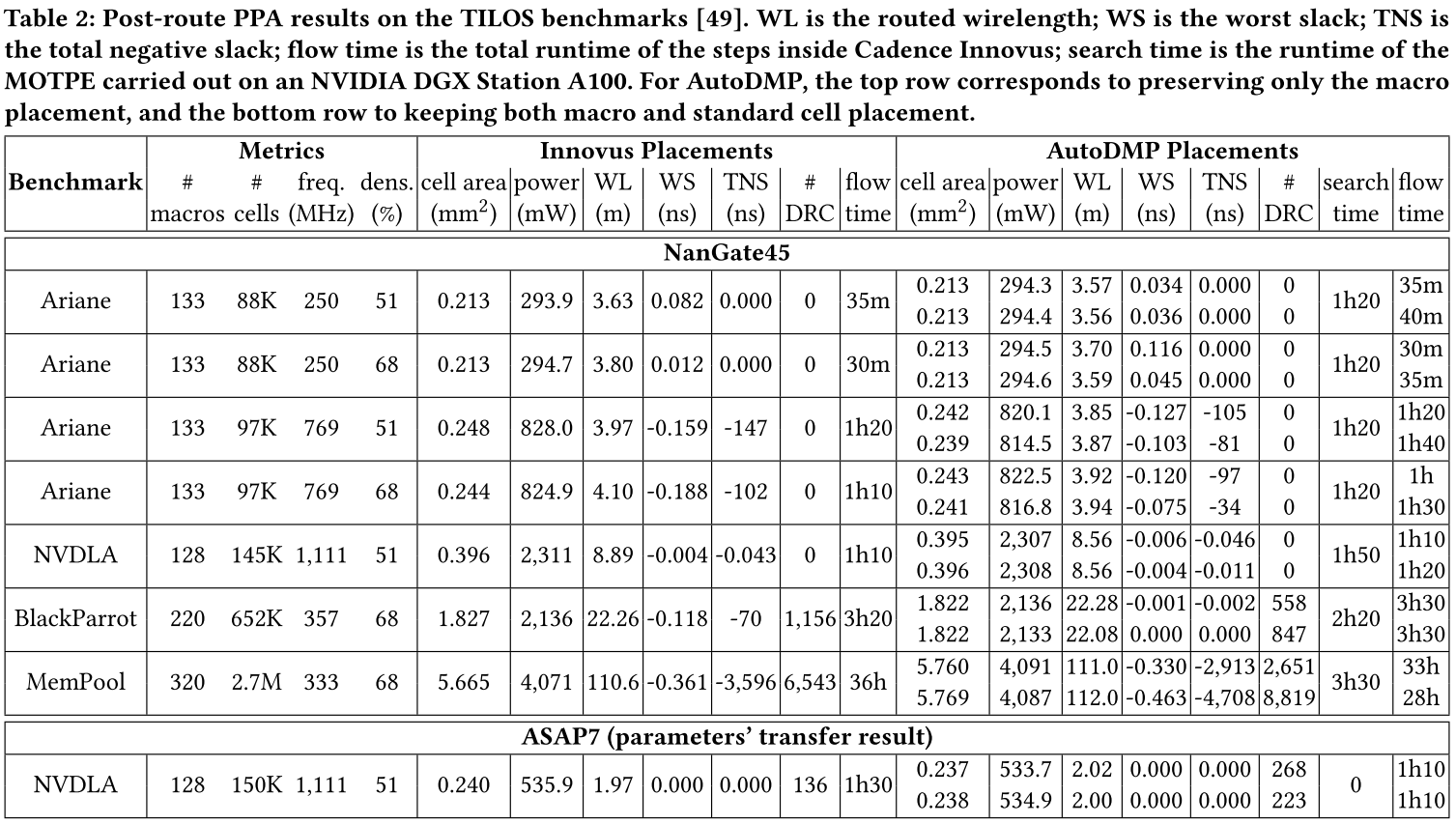
此处只是为了证明方法可行性。
Ariane 数据集测试布局对比
使用 Cadence Innovus 和 AutoDMP 获得的 Ariane 基准测试的布局。eg.图 6:

宏的放置并没有什么不同,并遵循传统的人性化规则,宏位于外围,远离 IO 引脚,为标准单元留下连续的空间。
MemPool Group 基准测试
使用 Cadence Innovus 和 AutoDMP 得到的 MemPool Group 基准测试的宏和标准单元放置的逻辑到物理映射和单元密度图。eg.图 7:

宏放置和逻辑组的物理排列方式都有相当大的不同。然而,AutoDMP 放置器会像商业工具一样将逻辑单元组物理地放置在一起。差别不大。
参数可传递性
将 NanGate 45 nm 上的 NVDLA 的最佳参数转移到更先进的开源 ASAP 7nm 工艺。只有宏光晕大小通过缩小它们来修改,以匹配新技术。eg.图 8:

额外展示
在此感谢 TILOS-AI-Institute 对 EDA 布局任务开源贡献
References – TILOS
Ariane and BlackParrot using AutoDMP, in both NG45 and GF12 enablements
-
Ariane133-NG45-68%-1.3ns
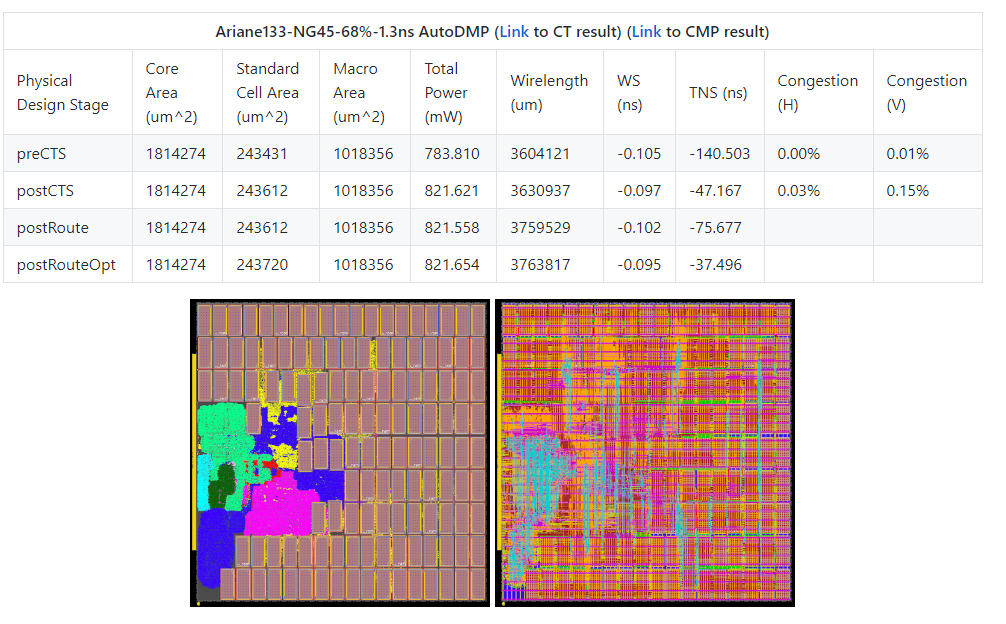
-
Ariane133-GF12-68%
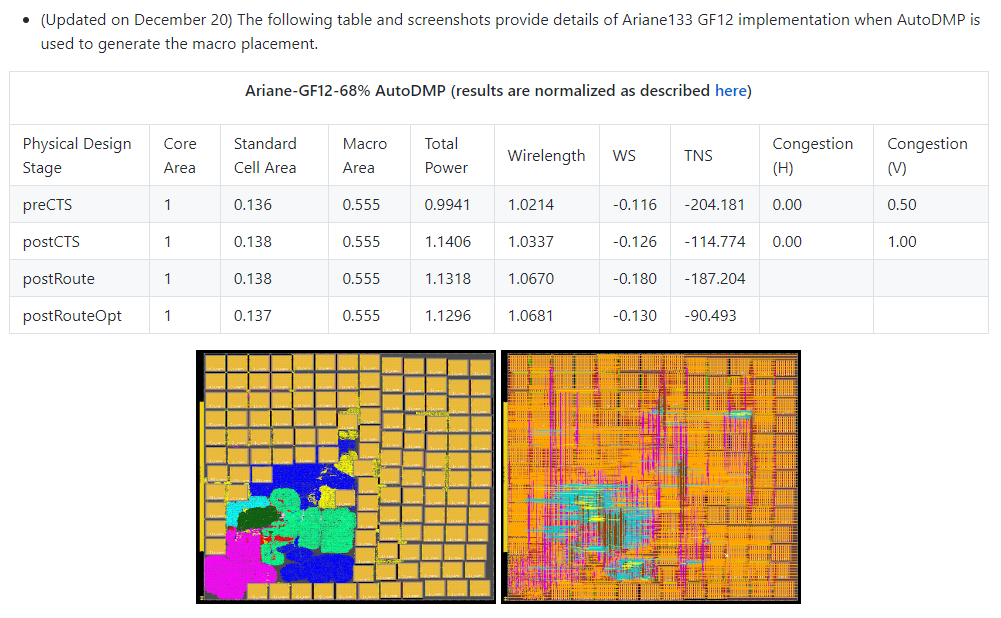
-
BlackParrot-NG45-68%-(bp clock)1.3ns
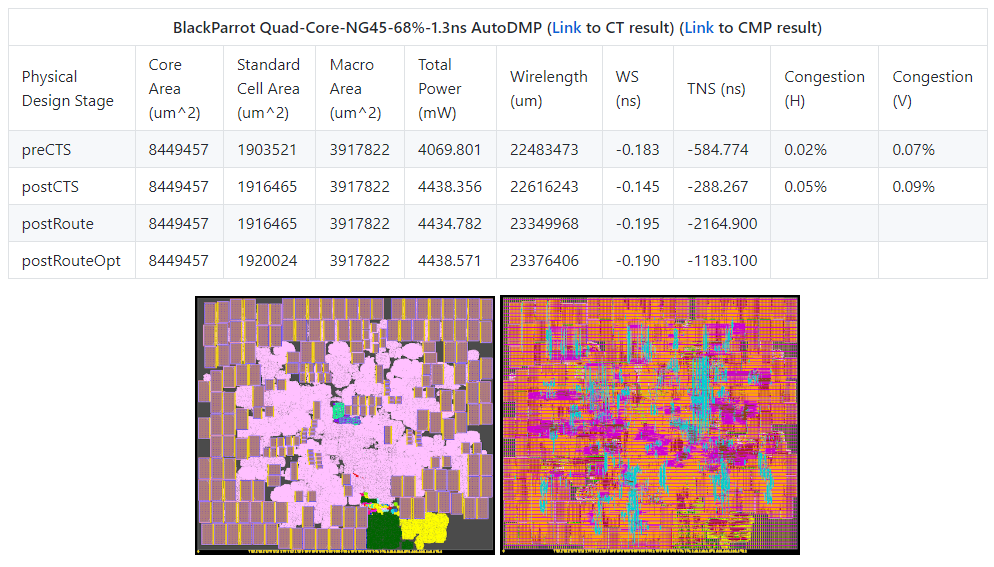
-
BlackParrot-GF12-68%