Reinforcement Learning within Tree Search for Fast Macro Placement
本篇论文发表在2024 ICML, 来自MIRA 团队,一作来自耿子介学长。
Introduction
宏布局结果影响芯片设计整体质量。在芯片布局任务中,巨大的设计空间仍然具有挑战,显著超过 Alpha Go。
现有布局分为基于优化和基于 RL 两个方面。
-
基于优化比如模拟退火和进化算法,可以有效探索设计空间接近最优布局结果。但是,为了避免宏单元重叠,往往需要一个后处理(Post-Process)过程,而且缺乏从过去经验学习能力(OS:ChipFormer其实已经有了经验池的做法),在质量和效率方面不能满意。
-
基于RL方法需要大量的反馈来引导,从而导致低效率训练。尽管ChipFormer试图通过Offine RL来解决效率问题,但是这种方法严重依赖大量专家数据,这些数据在现实中是稀缺的,限制应该方法用。而且不同芯片之间巨大差异需要广泛微调,阻碍了在工业场景中应用。
本文提出了一种新的采样效率框架(Sample-Efficient)—— EfficientPlace,用于快速宏布局。效率来自两个方面。双层学习内部优化框架(Bi-level Learning-Inside-Optimization Framework)。本文解释优化来源于宏布局过程中固有的两个方面,第一个方面,本质上是一个优化问题,寻找一个巨大的设计空间内最优解;第二个方面,搜索空间广阔性要求 RL 通过试错来学习和概括。
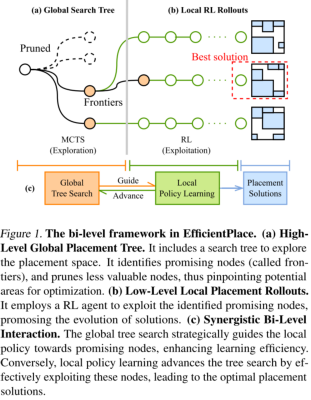
EfficientPlace 通过“双层学习内部优化框架(Bi-level Learning-Inside-Optimization Framework)”来利用这种两个方面。本框架有助于在一个搜索中累计在线经验。图 1 所示。
-
high-level:蒙特卡洛树搜索(MCTS)用于战略导航搜索。利用一种滚动前沿(rolling frontiers)机制引导RL代理(Agent)关注和利用有价值状态,增强精英解决方法。(os:此处rolling frontiers我并不知道怎么翻译。在树结构中,“front”通常指的是树的某个特定层次的所有节点。通常在BFS使用,搜索过程从树的根节点开始,逐层向下访问直到所有的层都被探索完成。每一层的所有节点可以被看作是那一层的“front”或“前沿”。文中rolling frontiers应该是想表达在搜索过程中,树的front是动态的)
-
low-level:利用RL代理学习和泛化能力,促进广泛探索。
Bi-level framework:由 MCTS 指导的定向优化和基于 RL 的自适应学习。
为提高采样效率,本文在 RL 代理(Agent)上做了两个关键增强。第一是采用 laiyao 提出 MaskPlace 这篇文章的 wiremask 线长掩码,来量化 HPWL 值,缩小探索空间,并且指导动作决策过程。 第二个方面,RL 中采用 Unet 算法,为了对芯片画布进行高分辨率控制,提高细粒度放置,提高放置质量。
Related Work
Optimization-based Methods for Placement
主要说的 shi yuqi 提出 WireMask-BBO 算法。
Learning-based Methods for Placement
GraphPlace、DeepPR、MaskPlace、ChiPFormer
Reinforcement Learning with MCTS
MCTS 与 RL 结合已经取得了一系列突破,比如 DeepMind 团队 AlphaGo,MuZero(os:其实 MuZero 是 model-based RL 和 AlphaZero 的结合),AlphaTensor,AlphaDev。
本文框架中,树搜索作为一个全局指导,而不是本地策略优化器。此方法优先寻找最优解,而不是学习全局策略。
Preliminaries
Macro Placement
一些基本指标,老生常谈,不细致描述,比如半周线长(HPWL)和拥塞(Congestion)。
HPWL
Notations
本文依然采用的排序宏面积大小,描述一下强化学习中基本参数。依然老生常谈,不细致描述。
Our Approach
4.1 节阐述学习集成到宏布局优化动机;4.2 节提出 bi-level framework 此双层架构;4.3 节深入研究了本文的高效 RL 架构。
Motivation
本文开始通过在宏布局上下文中基于优化和基于学习方法范例。
优化方法中 Wiremask-EA 通过变异操作,随机交换两个宏单元位置。(os:变异(Mutation)操作是在进化算法(EA)中引入多样性的重要手段。常见位翻转(Binary Flip),交换变异(Swap Mutation),数值变异(Numerical Mutation))Wiremask-EA 缺乏学习能力来处理看不见的状态,限制搜索采样效率。
基于学习方法主要指定决策,讲宏单元定位在中间各种转台,用神经网络泛化能力来实现探索和利用的平衡。此方法在开始未探索之前非常有效。但是 RL 从空画布开始独立展开,这会导致对次优状态偏差,并导致冗余计算。
EfficientPlace: The Bi-Level Framework
本文提出了 EfficientPlace,讲树搜索算法的精确性和 RL 算法灵活性结合。图 2 描述了模型结构。
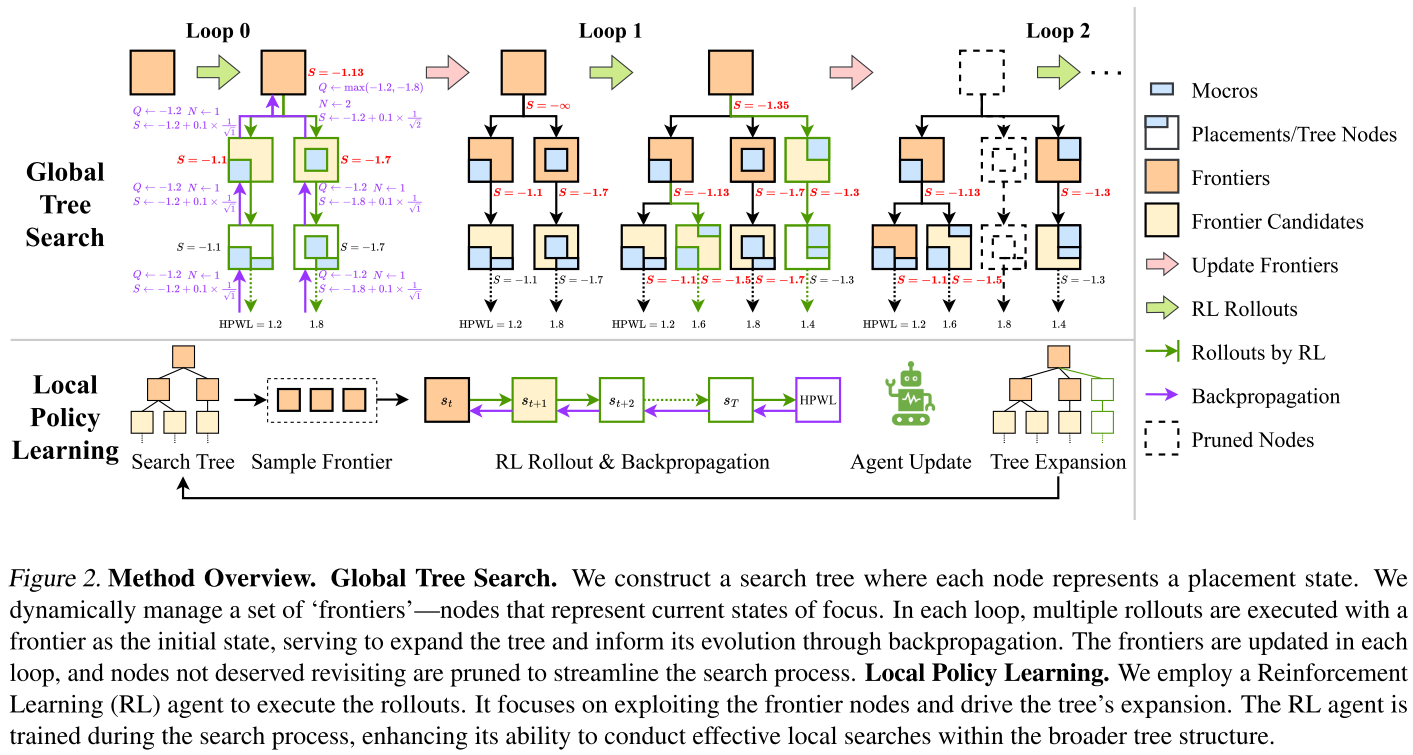
在 high-level 上,采用全局树搜索算法进行精确指导。重点是识别和利用有希望的状态。
在 low-level 上,利用 RL 的学习和泛化能力,促进有效的探索。
简称:MCTS 引导的直接搜索和 RL 驱动的自适应学习。
Global Search Tree
构造搜索树
将节点
Frontiers & Node Selection
采用 beam-search(集束搜索)策略进行节点选择,集中在一组称为“frontiers”节点上,表示
Local Policy Learning & Tree Expansion
每个 RL rollout 从选定边界节点
采用 PPO 算法更新 Agent,提高本地搜索效率。
Updating Frontiers
在一定数量的 rollouts 后,在下一个循环之前更新”Frontiers“。这种更新灵感来自于维护最佳解决方案池的优化方法。目的是保持
$$
\mathcal{F}{\mathrm{cand}}=\bigcup{s\in\mathcal{F}}\mathcal{C}(s)\setminus\mathcal{F}
$$
受 UTC 算法影响,将分数定义为:
其中
RL Agent Architecture
本文依然沿用了 laiyao MaskPlace 中的 position masks 和 wire masks。
Wiremask for Reducing Search Space
老生常谈,不再过多赘述。
U-Net for Fine-Grained Control
对画布网格精准控制对于精准的宏放置至关重要,本文采用 U-Net 作为策略网络。左侧用于编码,处理视觉输入和网表信息时间步长等嵌入。右侧为解码,输出策略概率。左侧特征融合到右侧层中,以便将有效输入信息传达给解码器,促进更精确控制。
此外,解码器采用双线性上采样,这种设计使得 RL 代理能够利用网格相对位置,提高探索精度和效率。通过上述模型结构,即使再高达 512 X 512 大型画布上也能实现有效训练,提高 HPWL 性能。
Experiments
Benchmarks and Settings
对比模型为:GraphPlace、DeepPR、SA、MaskPlace、ChiPFormer、WireMask-EA。
数据集为:ISPD05。
Main Results
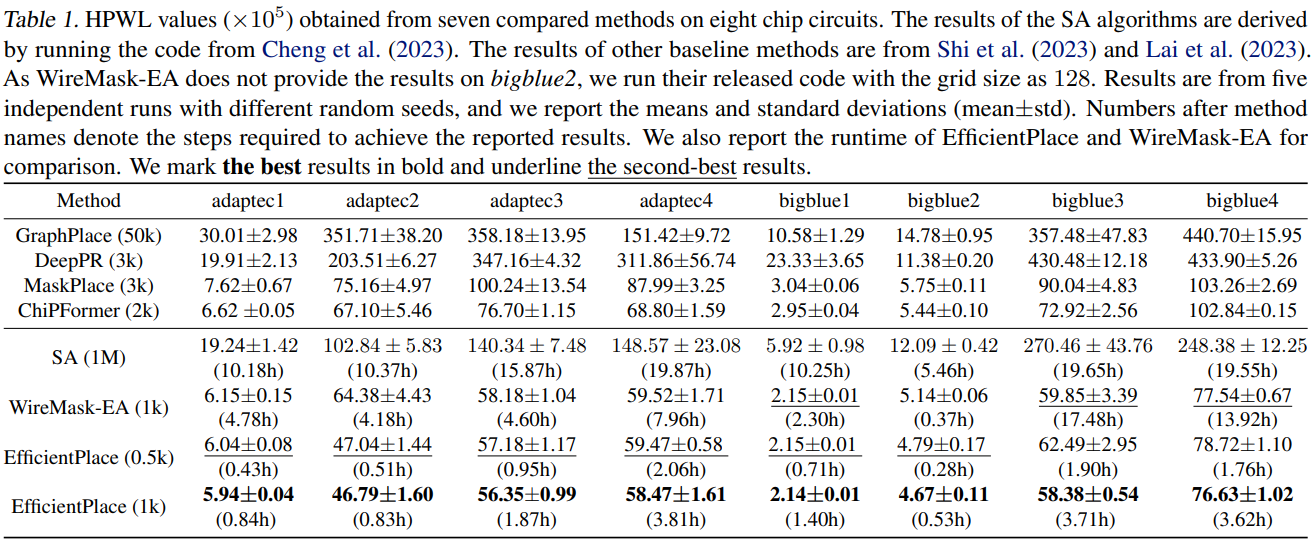
表 1 半周线长的结果。
Runtime & Step Analysis
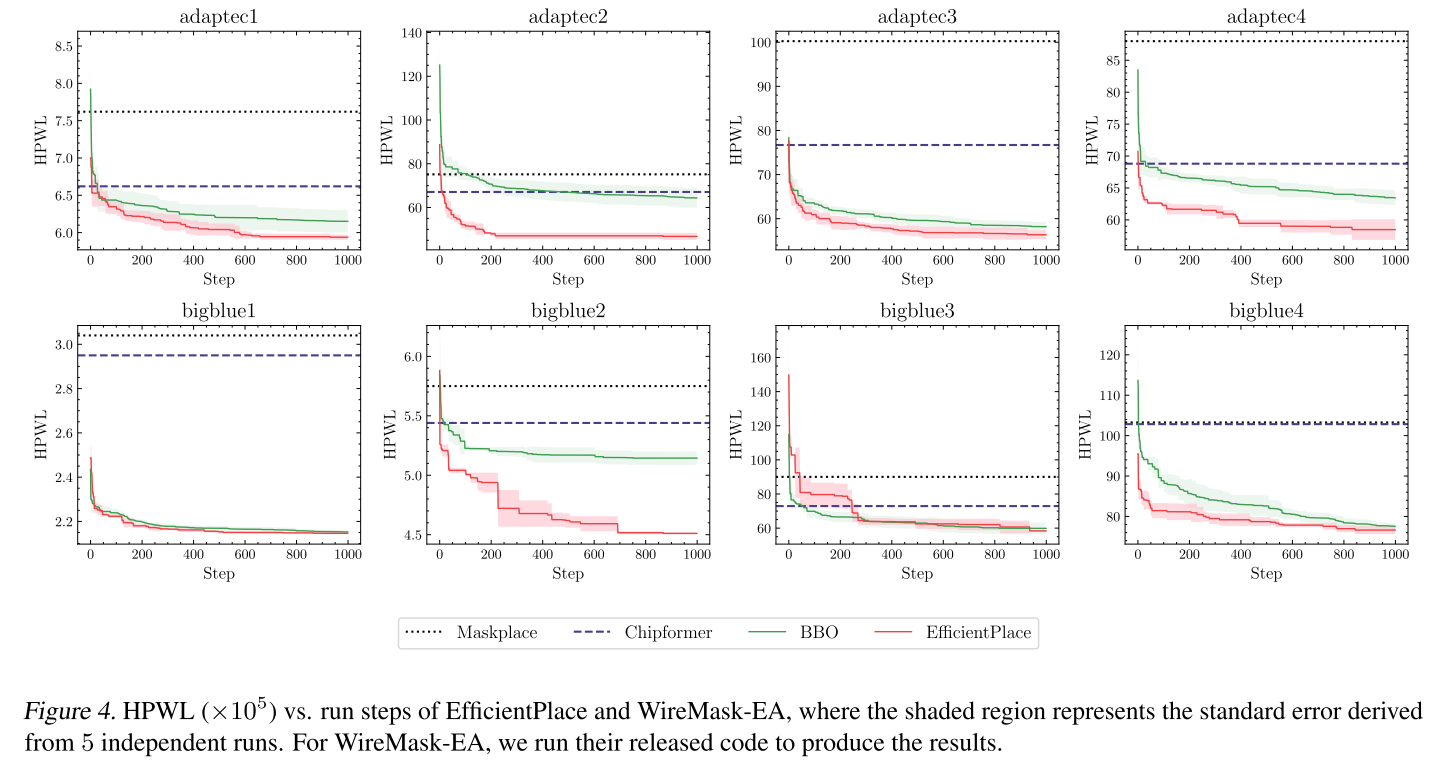
与 WireMaks-EA 对比 HPWL 与时间曲线。图 4。
Congestion Results
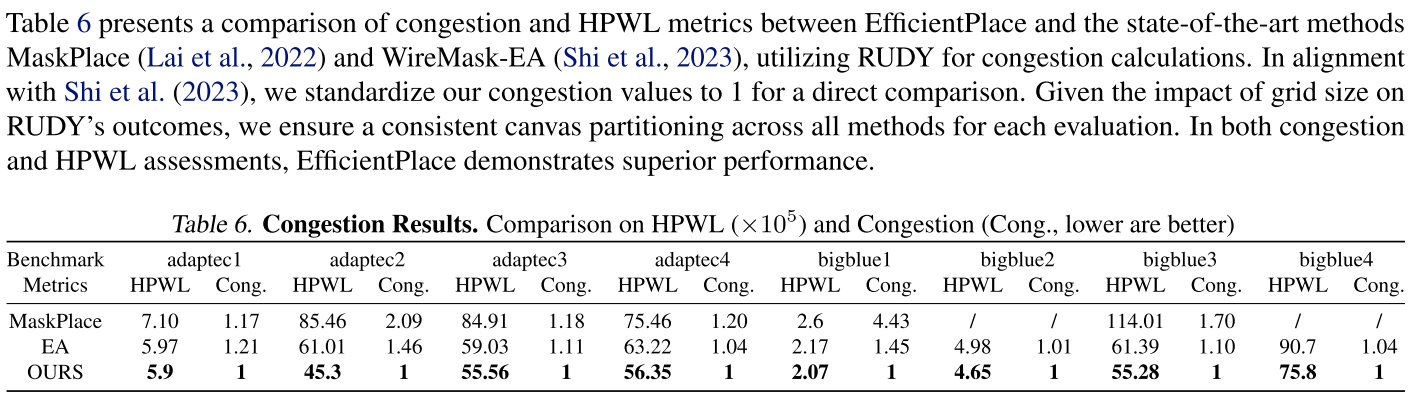
拥塞结果,见表 6。
Mixed-size Placement
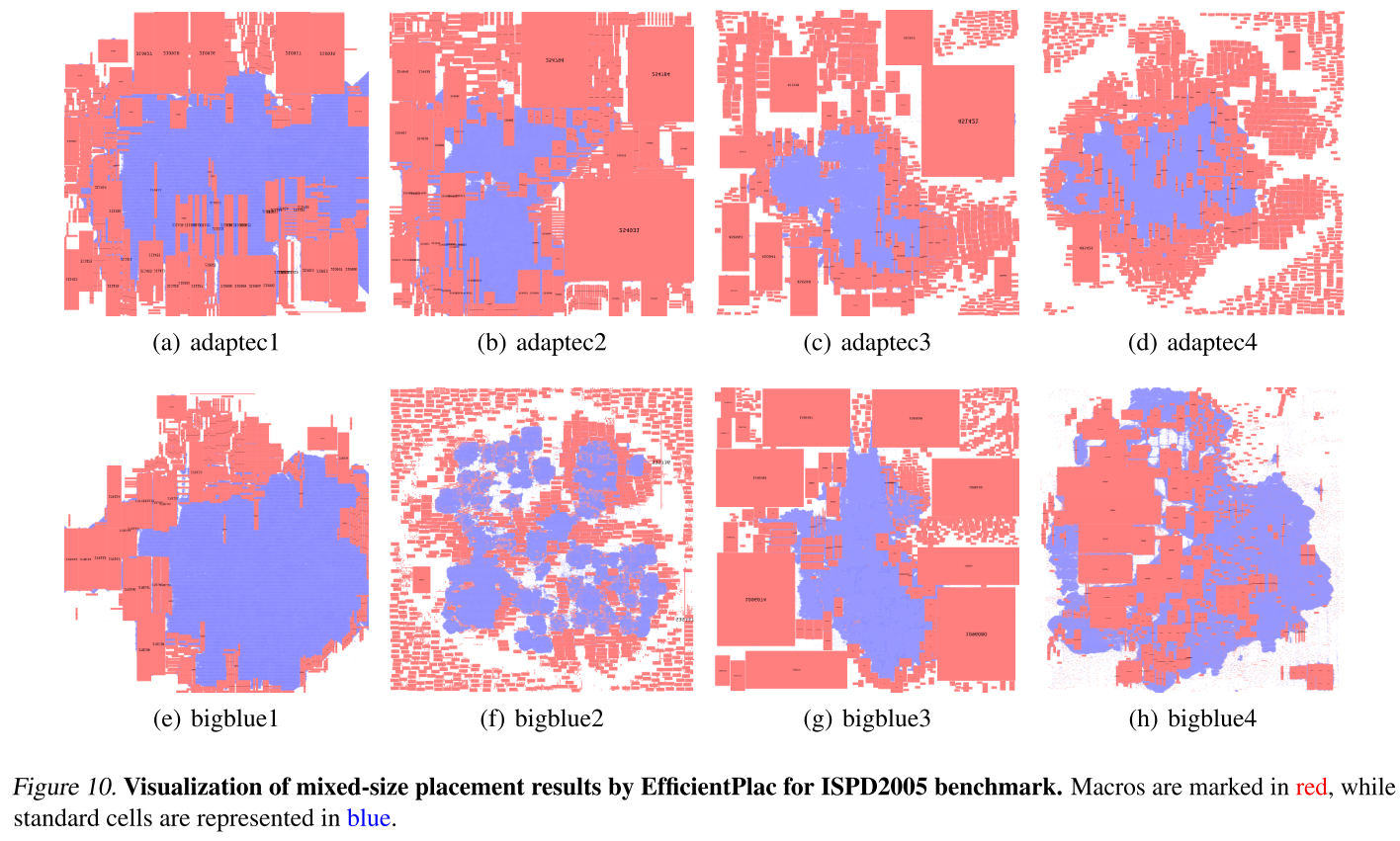
混合布局。EfficientPlace 宏单元放置 +DREAMPlace 标准单元放置。见表 5。

混合布局效果展示,见图 10。
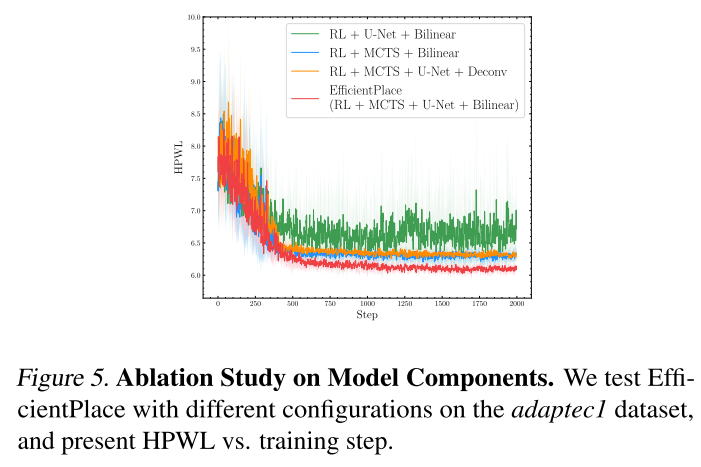
Ablation Study on Model Components
针对模型的消融实验。
-
RL + U-Net + Bilinear
-
RL + MCTS + Bilinear
-
RL + MCTS + U-Net +Deconv(用反卷积替代双线性上采样,虽然参数更多,但是效果更差。双线性上采样为相邻网格产生更接近的动作概率,有效捕获动作之间的空间关系,更有效探索)
-
RL + MCTS + U-Net + Bilinear
见图 5。
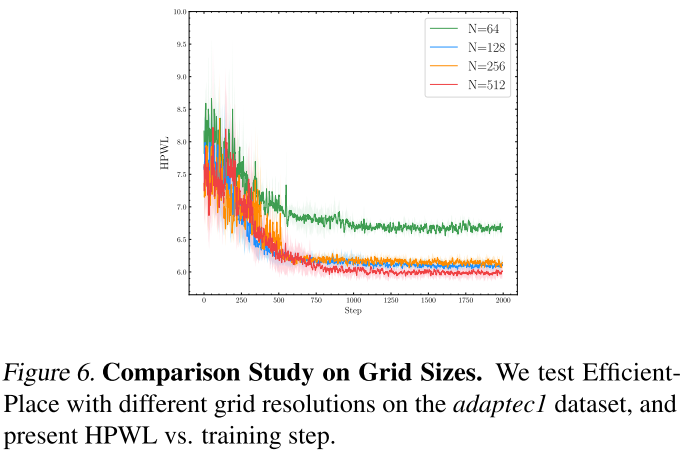
Comparison Study on Grid Sizes
EfficientPlace 展示了在不同网格大小上差异,证明更精细的网格,学习曲线越好,有更小的 HPWL 参数,证明了 EfficientPlace 在网格细粒度上有效性。见图 6。