AnalogCoder: Analog Circuit Design via Training-Free Code Generation
论文链接 arvix
代码 code
Introduction
模拟电路在现代集成电路中不可或缺,有助于精确的传感、放大和滤波。对于将数字系统与物理环境联系起来至关重要。
大语言模型(LLM)给自动芯片设计带来了机遇。现有的研究主要集中在两个任务:Verilog 代码生成与校正;设计脚本编写。LLM 在生成 Verilog 代码时候不如广泛的 c 或者 python 代码这么好。使用 python 或者 tcl 编写脚本在各个阶段调用 API 促进芯片设计过程,此工作主要用于数字电路设计,如表 1:

模拟电路设计比数字电路设计提出了更多挑战,包括:
-
复杂性。与数电逻辑门设计不同,模电包括各种组件,类似电压和电流源、MOSFET、电阻和电容。微小的调整都会显著改变电路功能。
-
抽象层次。数电设计可以在 Verilog 等高抽象级别编写,直接分配功能,无需硬件底层组件。相比之下,模电需要在设计代码中直接表示物理组件,需要一个更详细和特定于组件的设计过程,更难有效利用 LLM 帮助。
-
语料库数据量(Corpus data volume)。虽然数电的 Verilog 在 Github 上占不到 0.1%,但模电主要语言 SPICE 更不常见。
减轻传统手动模拟电路设计缺点,弥补 LLM 中现有差距,引入 AnalogCoder,一种新的免训练 LLM 代理(LLM-based agent),通过生成 python 代码实现模电设计。进一步提高 LLM 设计能力,提出特定领域的提示工程(doman-specific prompt engineering)、反馈增强的设计流程(feedback-enhanced design flow)、电路设计语料库(circuit tool library)。大大提高设计成功性。
本项工作中,优先考虑模拟电路正确功能,避免广泛的参数优化。实验证明,AnalogCoder 可以自主解决 24 个模电设计的 20 个。本文总结三个贡献:
-
介绍 AnalogCoder,第一个基于 LLM 的模电设计。通过 python 代码设计模电。
-
开发了反馈增强的设计流程(feedback-enhanced design flow)和电路语料库(circuit tool library),提高 LLM 设计模电能力。
-
介绍了第一个用于测试 LLM 模电能力的数据集,其中包括 24 个独特电路,是 ChipChat 的三倍,比 VeriGen 多提供 40% 电路。为未来科研提供增强资源。
-
Preliminary
Analog Circuits
与专门处理离散二进制信号数电不同,模电处理连续信号。如图 2 所示:

模拟放大器被设计为增强输入信号幅度
-
运算放大器(op-amp)被设置为加法器时,可以实现函数
。 -
运算放大器(op-amp)被设置为积分器时,可以实现函数
,其中 表示电路电阻和电容相关的时间常数。
模电需要通过仿真,增益,共模增益和相位差等属性确定合格。
Code Representation for Circuits
为了便于模电设计描述和仿真,引入 SPICE。在 SPICE 语法中,基本结构是元件和节点,见图 2(SPICE Code): 元件是指各个电子元件,如电阻器和晶体管,节点表示元件互连的点,如图 2(Circuit Diagram):
元件是指各个电子元件,如电阻器和晶体管,节点表示元件互连的点,如图 2(Circuit Diagram):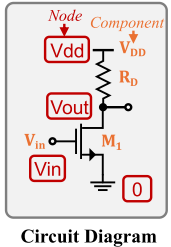 放大器包括四个元件: 两个电压源
放大器包括四个元件: 两个电压源
N 沟道 MOSFET
电阻负载
在 SPICE 代码中四行描述了这些元素开头,后续跟着元素连接节点。见图 2(python code):

PySpice 将 SPICE 代码和 python 编程语言集成,扩大 SPICE 的可用性。
Our Approach
Method Overview
特定领域的提示工程(doman-specific prompt engineering)、反馈增强的设计流程(feedback-enhanced design flow)、电路设计语料库(circuit tool library)如图 3 所示:
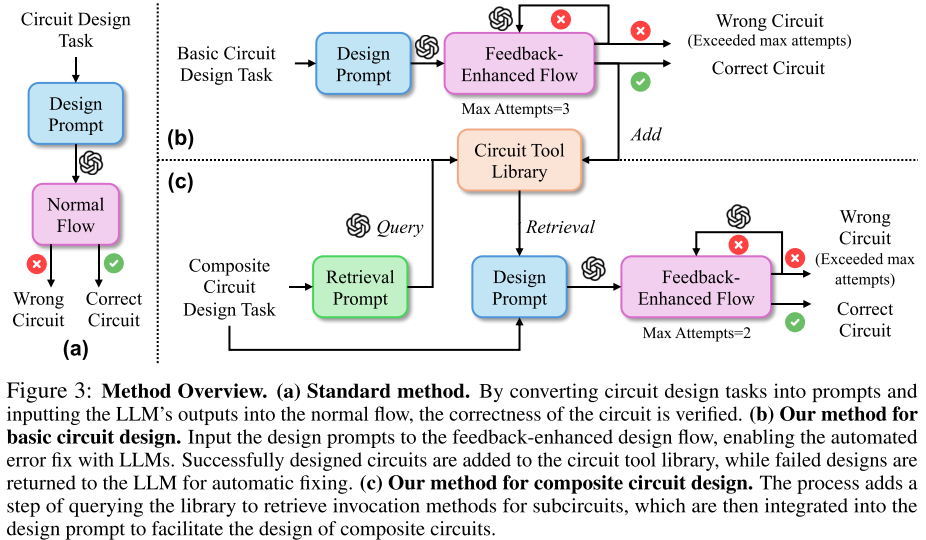
特定领域的提示工程(doman-specific prompt engineering)通过策略性、解决问题性提示增强 agent 思维能力;
反馈增强的设计流程(feedback-enhanced design flow)使用多个检查向 agent 提供错误反馈,促进 LLM 对失败设计纠正。
电路设计语料库(circuit tool library)是一个模块化的子电路库,系统将设计电路组织为工具,使 LLM 能够直接检索和复用复杂的电路设计。
Prompt Engineering
Prompt engineering 包括三个主要方法:
-
编程语言选择(programming language selection)
-
上下文学习(in-context learning)
-
思维链(Chain-of-Thought)
LLM 中 python 性能超过其他语言,比如代码生成(Code-generating)LLM,CodeLlama、WizardCoder 主要基于 python 微调,而且 Github 上没有太多 SPICE 代码数据。减轻这种限制,主要提示 LLM 生成与 PySpice 库兼容的可执行 python 代码。
此外集成了上下文学习(in-context learning)来增强电路设计,提供了一个带有源和电阻负载的两级放大器的详细示例作为一次性学习。这个例子促进 LLM 学习和模仿,优化输出,最大限度减少错误,所有设计任务与提供示例不同,保证评估的公平性。
此外采用思维链(Chain-of-Thought)促进 LLM 生成详细设计计划,包括必要的元件和互连。简化设计任务。例如附件 2:


Feedback-Enhanced Design Flow
由于 LLM 生成代码中出现各种错误,因此引导 LLM 根据错误消息纠正生成代码至关重要。对于模电设计而言,除了执行 SPICE 仿真可能出现错误,还需要额外验证电路相关信息确保设计正确性。
当设计失败时,将 python 代码运行错误或者特定电路测试结果返回给 LLM,如图 4 所示:
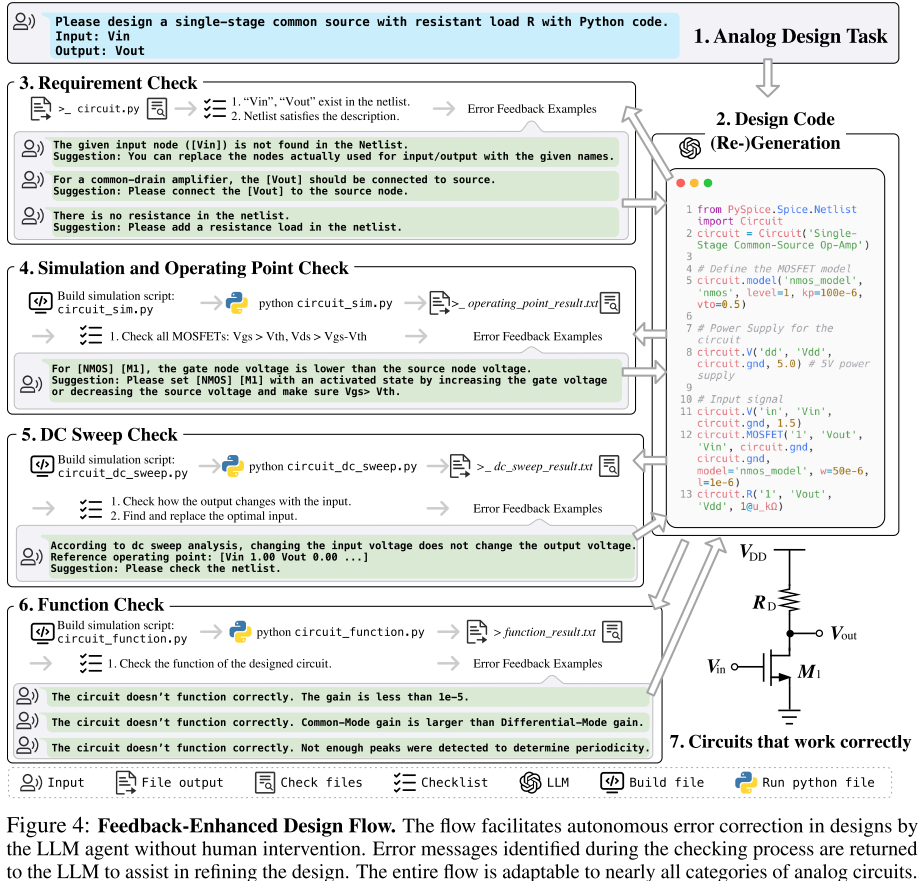
将反馈增强流程(Feedback-Enhanced)分为四个阶段:
-
需求检查(requirement check)。验证生成代码是否符合基本要求,e.g. 是否存在必需的输入输出,包含必要电路组件。
-
模拟和工作点检查(simulation and aperating point check)。检查最初评估所生成的模拟电路是否正确执行模拟。仿真通过,得到节点静态工作电压。检查这些工作点电压可确保MOSFET晶体管处于正确的运行状态。
-
直流特性扫描(DC sweep check)。通过改变输入节点电压观察输出节点对应变化执行直流(DC)分析,验证输入到输出信号路径完整性。该方法还有助于识别最佳偏置电压,提高设计成功率。
-
功能检查(function check)。模拟特定输入波形并观察输出,验证模拟电路基本功能。
如附表 6 所示:

Circuit Tool Library
随着模电设计任务越来越复杂,实现代码越来越复杂,LLM 生成正确电路越来越有挑战性。为解决此问题,基本电路封装到 SPICE 代码的子电路模块中,便于集成到更多符合组件。本文采用了一种电路工具库(Circuit Tool Library),该工具库存储了正确设计的子电路,以便在复杂设计中使用,如图 5 所示,本文方法包括两个主要过程,向库中添加电路(Top)和从库中检索电路(Bottom)。
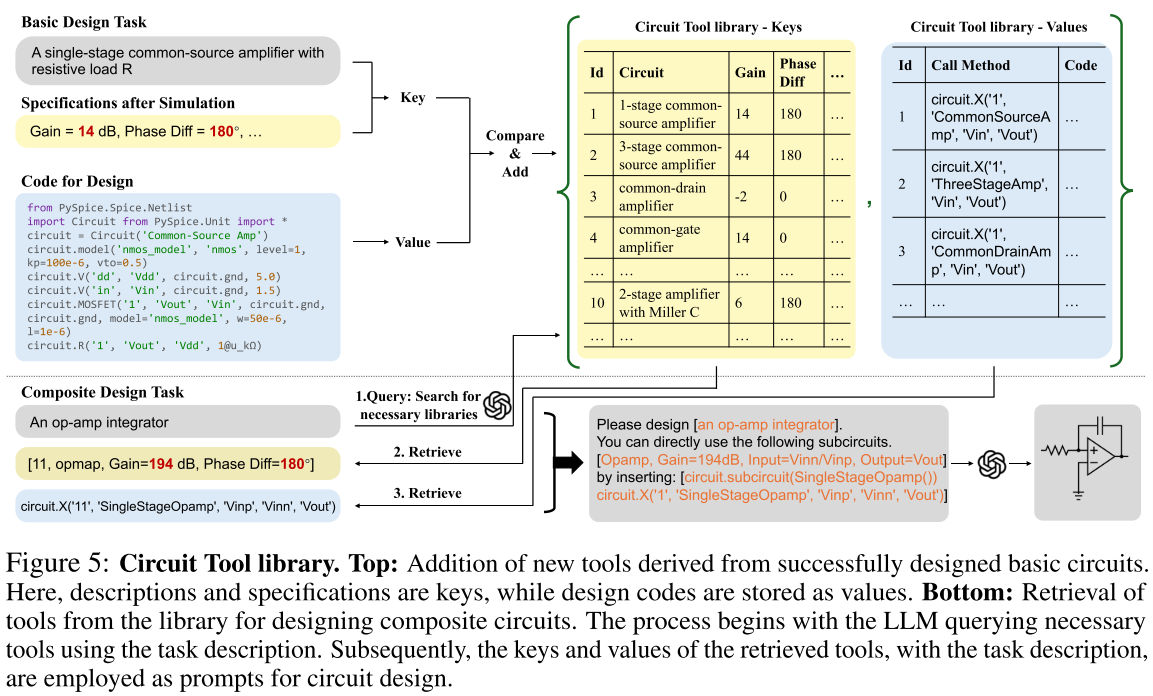
一个 LLM agent 完成一个基本电路设计任务后,将电路代码和仿真结果中规范添加到电路工具库中。如果一个电路任务已经多次成功完成,根据关键规格(如增益)存储最佳电路设计。
任务描述和电路信息存储为 key,代码和调用方法存储为 value。在复合电路设计中,任务描述用于制定查询提示,使得 LLM 能够检索所需子电路索引,然后根据这些索引获取所有对应的规范和调用方法。然后将这些信息和任务描述结合,重新输入到 LLM 以设计电路。
如上述图 5,当设计运算放大器积分器时,LLM 查询并检索与所需子电路(单级运算放大器)相对应索引。随后任务描述沿着该子电路的相关信息一起输入到 LLM,LLM 生成运算放大器积分器的设计代码。
Fine-tuning
由于模电数据集稀缺以及 GPT 辅助数据生成启发,本文收集由 GPT-3.5,GPT-4o 和 Llama-3 创建的成功电路设计样本,以提高提供的 API 微调 GPT-3.5。
本文收集了每个任务的成功设计,并使用文本矢量化(text vectorization TF-IDF)分为三类。从每个类别中选择一个设计,并与输入提示配对以形成初始配对,然后通过问文本过滤进行优化以创建微调数据。交叉验证技术(Cross-validation techniques)被应用以确保在微调中使用的任务被排除在测试集之外。更多细节见附件 6:


Experiments
本文广泛评估 LLM 在模电设计中能力,包括 Mixtral-7×8B、CodeLlama-70B-Instruct、Wizardcoder-33B-V1.1、Llama3-70B、DeepSeek-V2、GPT-3.5-turbo、GPT-4-turbo、GPT-4o。
其中 CodeLlama 和 WizardCoder 为代码生成 LLM,微调在 Llama2 和 StarCoder 上面。
Llama-3 和 DeepSeek-V2 是最新开源 LLM。
WizardCoder、DeepSeek-V2、Llama-3 在人类评估代码任务上优于 GPT-3.5。
实验在 4 个 NVIDIA A100 GPU 评估。
Metrics
本文使用“Pass@k”作为代码生成任务评估量。“Pass@k”被定义为 k 次独立实验中正确生成的比率,值越高越好。
本文进行
其中
对于开源 LLM 和 GPT-3.5,本文设置
Benchmark
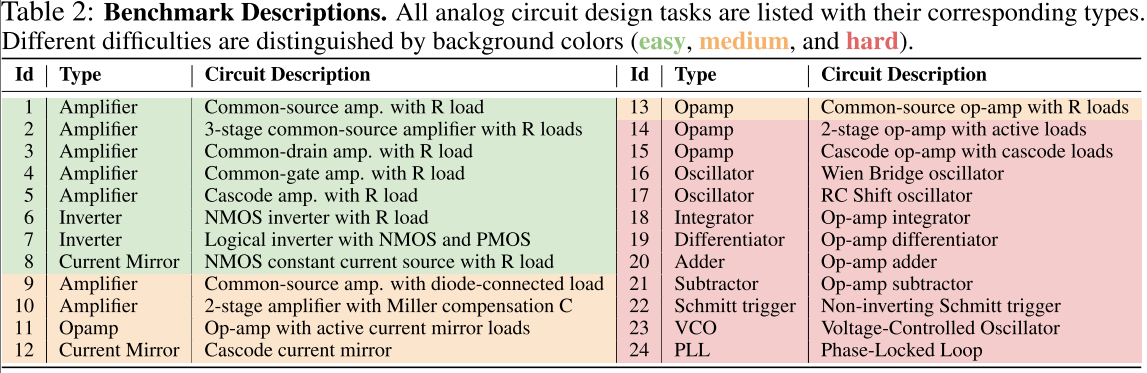
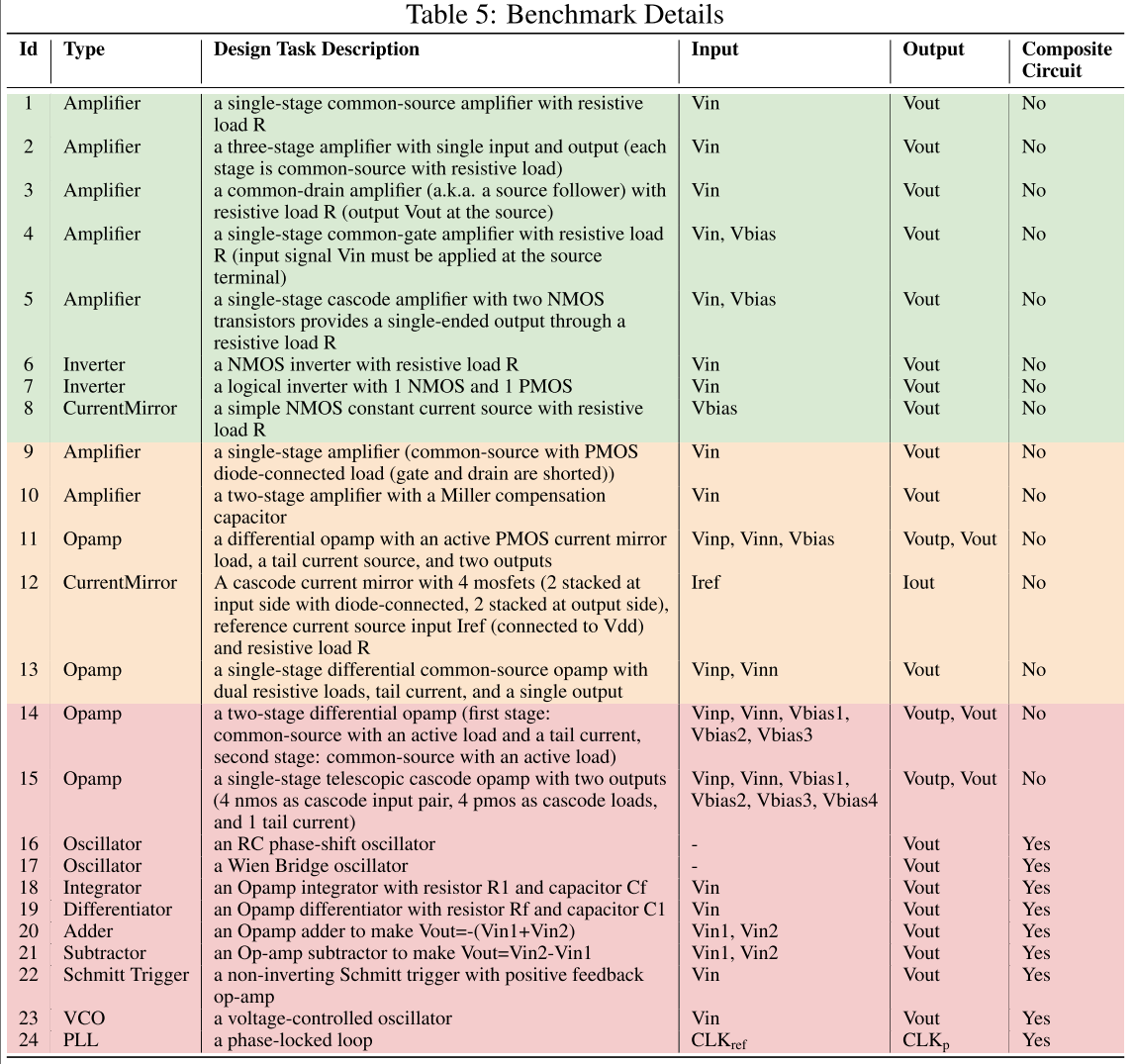
任务 1-15 为基础电路,16-24 为复合电路,详细见表 2:
更多细节见附件 1:
Main Results
主要结果。表 3 将本文 LLM agent AnalogCoder 与其他 LLM 方法进行比较,AnalogCoder 基于 GPT-4o,并结合即时工程(prompt engineering),流程反馈(flow feedback)和电路工具库(circuit tool library)。
为了公平对比并突出工具库影响,本文将所有策略应用于所有 LLM,但特别将电路工具库(circuit tool library)从 GPT-4o 中移除,排除影响。
结果表明,与 GPT-3.5 相比,最新开源模型 Llama-3 和 DeepSeek-V2 在电路设计上表现略微优秀成绩。然而其他开源模型与 GPT-3.5 相比仍然存在一定差距,尽管有些模型在正常 python 代码任务中超过 GPT-3.5。这是主要因为电路设计需要编码能力和特定背景知识;因此,一般的 LLM 往往表现得更好。GPT-4o 仍然是模电设计中最佳 LLM。受益电路工具库(circuit tool library),GPT-4o 和 Llama-3 可以进一步利用现有电路设计更具挑战性的复合电路,从而显著增强设计能力。更多细节见附录 7:
Additional Results
LLM 在模电设计能力比较,见表 10:
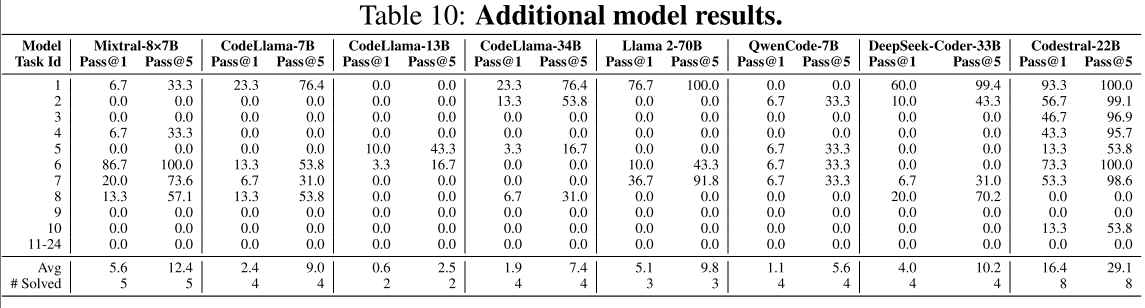
本文还比较了带电路工具库(circuit tool library)的 GPT-4o 和 AnalogCoder 之间的结果,见表 11:
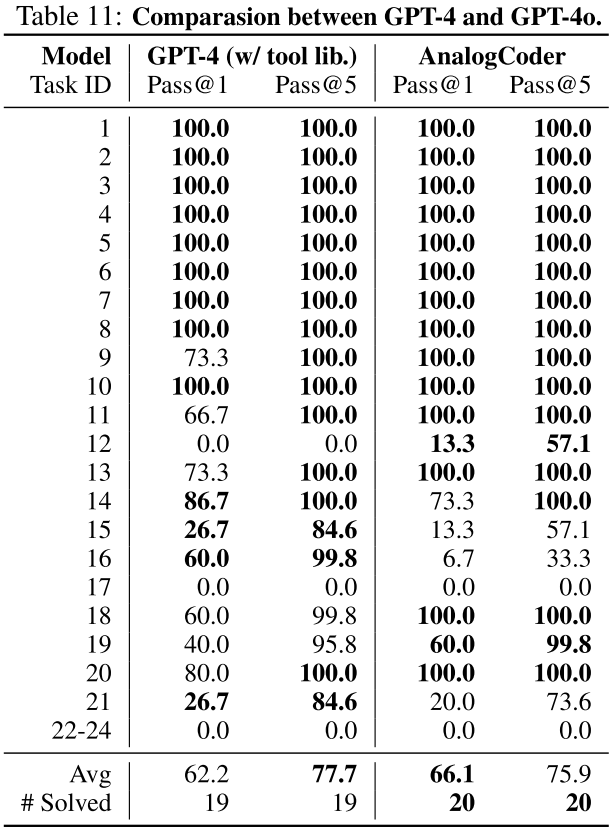
由于模型大小和相应的训练数据,这些模型只能成功设计不超过 4 个模拟电路,表 10 中未显示其他一些型号,包括 Mixtral-7×8B(2 个已解决)、Llama 3-8B(1 个已解决)、Qwen-1.5-110B(1 个已解决)、Llama 2-7B, 13B(0 个已解决)。
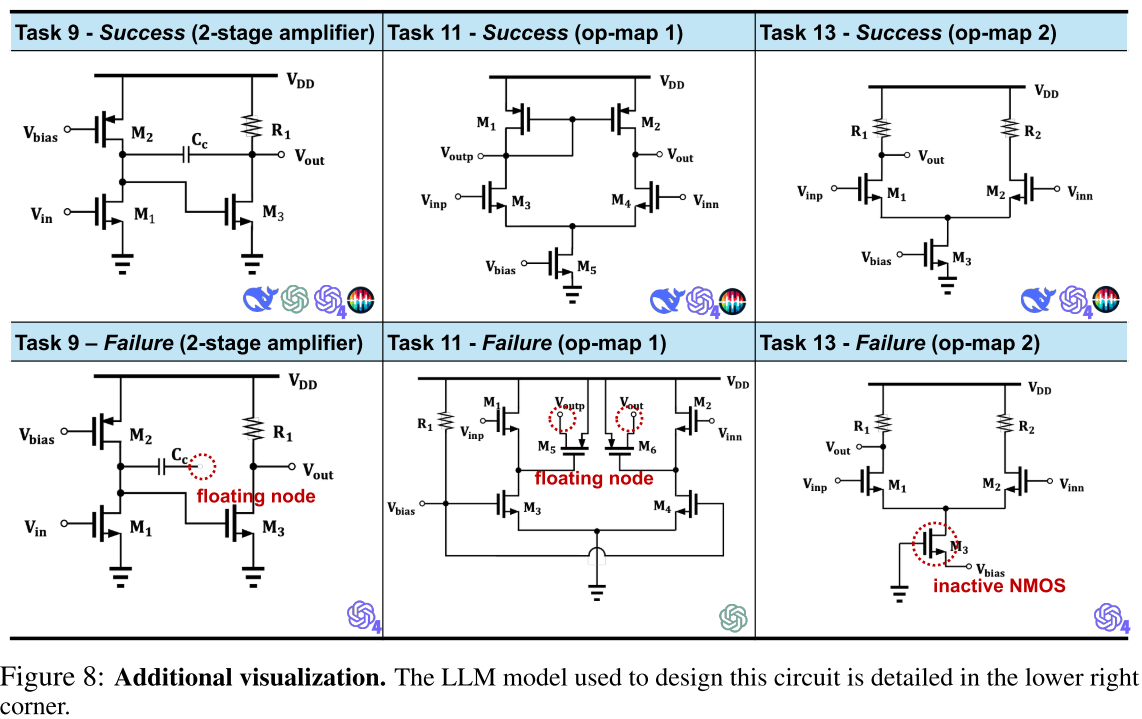
Additional Visualization
图 8 呈现了附加的可视化:
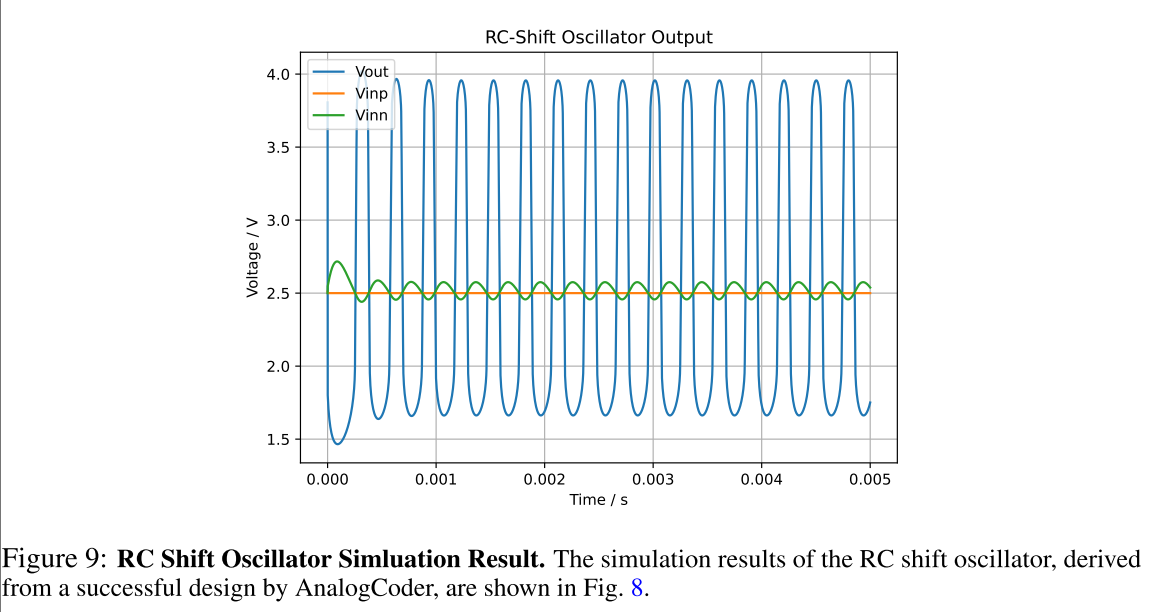
还由 AnalogCoder 提出一个由模拟编码器实现的 RC 位移振荡器仿真过程中产生波形,如图 9 所示:
Ablations
本文使用 GPT-3.5 模型评估了方法中各个组件的有效性,结果见表 4:
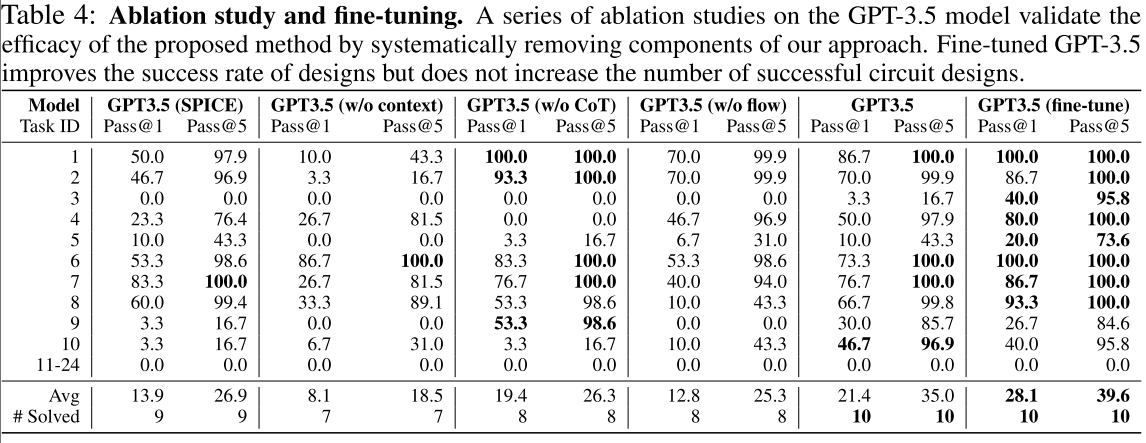
特别来说,“GPT-3.5(SPICE)”指的是 GPT-3.5 模型,其中 LLM 被提示生成 SPICE 代码而不是 Python 代码。“GPT-3.5(无上下文)”和“GPT-3.5(无 CoT)”这两个变体分别探讨了在提示中省略上下文信息和思维链推理时对性能的影响。此外,“GPT-3.5(无流程)”表示一种设置,即本文提出的设计流程未被使用,仅对第一批生成的代码进行功能测试。研究结果一致表明,去除这些组件会导致设计性能下降。
Fine-tuning
本文采用 3 折交叉验证微调评估(3-fold cross-validation),使用两个设计任务子集进行微调,剩余一个用于测试。微调使用 GPT-3.5 的 API,并进行两次迭代。结果见上述表 4,经过微调的 GPT-3.5 通常在设计任务上表现更好,因为微调通过正确示例标准化设计输出,并减少了常见的语法和设计错误。然而,由于 GPT-3.5 基础模型固有的限制,当数据有限时,微调模型在设计额外电路时会遇到困难。
Visualization
几个成功和失败的电路设计图在图 6 中,图地标指示相应的 LLM。观察到即使是最轻微的差异也会导致电路无法工作。
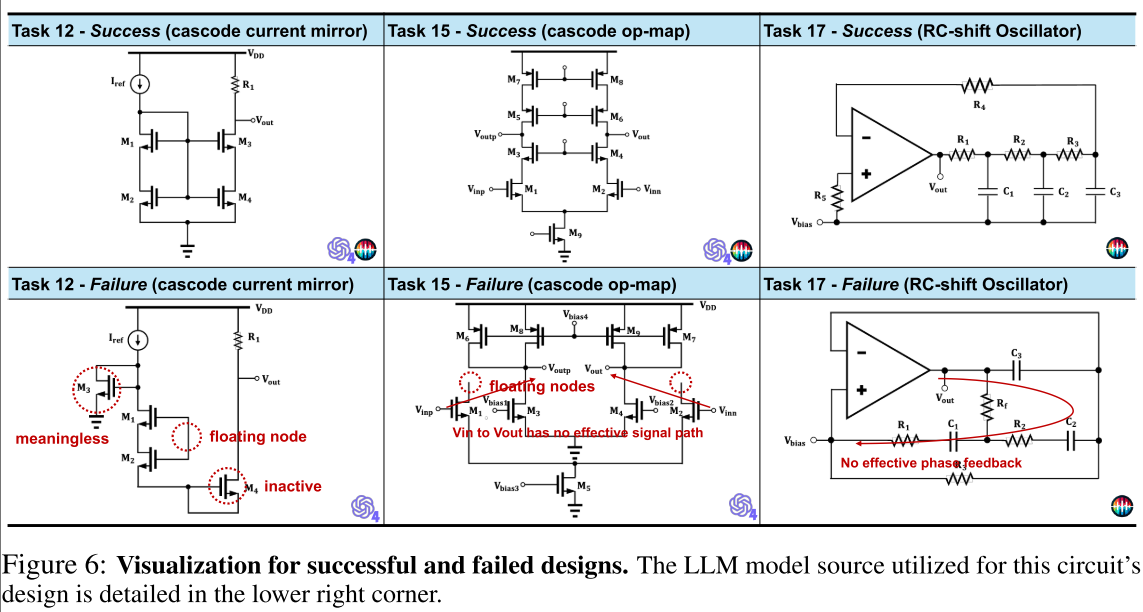
更多的结果见附件 8 的图。
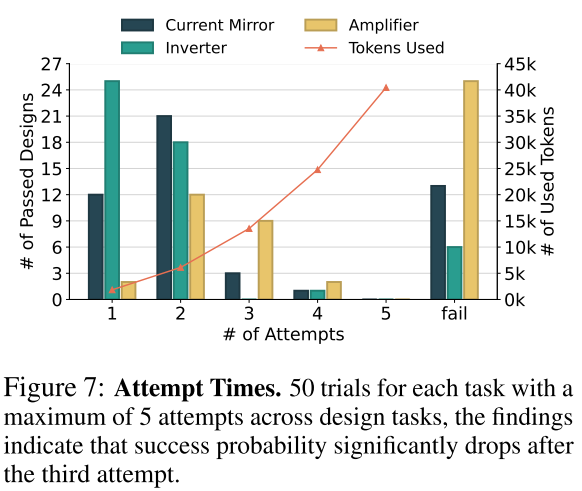
Attempt Times
尝试次数是一个用于最大化成本效益比的超参数。我们测试了三个任务(任务 ID=7、8、10),并使用 GPT-3.5 进行了 50 次试验,每次试验最多尝试 5 次。图 7 显示了 50 次试验中成功设计尝试的分布情况。结果显示,大多数设计在三次尝试内完成。如果在此限制内未完成设计,则 LLM 的进一步尝试成功的可能性很小,并且 token 消耗继续上升。因此,我们将默认尝试次数设置为三次。复合电路的设计尝试次数被限制为两次,因为它们涉及更复杂和具有挑战性的修复,并且具有较高的生成成本。见图 7: