GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models

前言
本篇文章来自 GIT 佐治亚理工 Yingyan (Celine) Lin [Team]老师。发布在 2023 ICCAD。此外 lin 老师还被受邀 2024 DAC presentation ,提出 LLM4AIGChip 由两个关键组件组成:Data4AIGChip和 GPT4AIGChip。
-
Data4AIGChip: Data4AIGChip tackles the issues of dataset scarcity and quality in LLM-assisted hardware design by creating high-quality, specialized datasets, thereby augmenting the effectiveness of LLMs in AI accelerator design.
-
GPT4AIGChip: GPT4AIGChip focuses on employing LLMs to automate the design and verification processes of AI accelerators, leveraging the advanced capabilities of LLMs to streamline and simplify these tasks.
Publication
Introduction
人工智能对专用 AI 加速器(AI accelerators)迫切需求。然而设计专用 AI 加速器仍然是一项艰巨和耗时任务。此外使用现有工具对所需硬件专业知识对非专家来说是一个巨大挑战。限制 AI 加速器设计扩展到一般 AI 开发者,造成 AI 算法速度和 AI 加速器之间差距越来越大。
本论文从 LLM 上找到灵感,并启发这个研究中心问题:“我们是否可以利用 LLM 力量自动化 AI 加速器设计” (“Can we harness the power of LLMs to automate the design of AI accelerators?”)
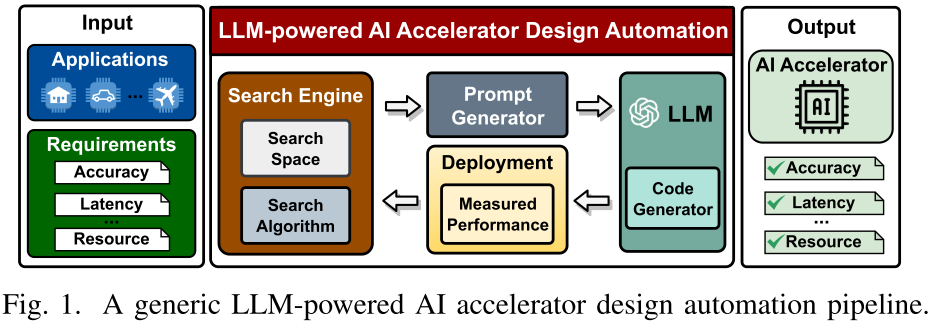
该论文提出 GPT4AIGChip —— GPT for AI Generated Chip,采用人类自然语言作为设计指令,而不是依赖特定领域语言,对不熟悉硬件的人更容易设计 AI 加速器。论文贡献如下:
-
本文调查了现有 LLM 对 AI 加速器设计限制和能力,了解当前位置,并由当前 LLM 设计 pipeline 提出见解,提出 GPT4AIGChip,第一个由 LLM 驱动的 AI 加速器设计自动化框架。
-
确定 LLM 当前 3 个见解(Insight):
- 对长代码处理:当前的 LLM 在处理长代码时存在困难,尤其是对于那些不常见的高级合成(HLS)语言。这表明在设计空间中需要将不同的硬件功能解耦,以便更好地处理这些长期依赖性。
- 数据稀缺与模型训练: 鉴于高质量注释数据的稀缺性,对开源大型语言模型进行有效的微调变得具有挑战性。因此,结合使用上下文学习和典型的闭源但强大的语言模型的逻辑推理能力,是一个更为有效的选择。
- 增强提示质量: 对于大型语言模型,关键是要用高质量的示例来增强提示,这些示例应与输入的设计指令的上下文相关联。这可以帮助模型更准确地理解和生成所需的输出。
-
GPT4AIGChip 构建一个由 HLS 编写的分离加速器设计模块,讲加速器设计分离成不同硬件模块和功能,首次实现由 LLM 驱动 AI 加速器设计自动化。
-
GPT4AIGChip 配备演示增强提示(demo-augmented prompt),利用强大 GPT 模型上下文学习(in-context learning)和逻辑推理(logical reasoning),实现 LLM 支持加速器空间探索。
Where We Are: The limitations and capabilities of current LLMs for AI accelerator design
A. An Overview of the Assessment
LLMs 虽然在生成任务(e.g. Q.A, language translation, chatbot dialogues)非常出色,但在处理预训练中较少遇到的语言和任务上能力未解决。
为了有效利用 LLMs 自动化 AI 加速器设计,了解当前最先进的 LLMs 的能力和局限性是至关重要的。这样的理解可以帮助避免过分乐观或悲观的看法。评估旨在提供这种理解,为未来在 LLM 驱动的自动化 AI 加速器设计方面的创新奠定基础。
文中首先识别了现有 LLMs 在 AI 加速器设计方面的常见局限性,然后验证了在注释过的硬件代码(如 HLS)上微调开源 LLMs 是否能提高它们对硬件代码和设计的理解。最终,考虑到在这两步中识别出的缺陷,重新考虑了 LLMs 在实际 AI 加速器设计自动化中能够有效利用的能力。这种评估和实验方法有助于更精确地利用和发展 LLM 技术在特定高技术领域的应用。
B. Failures and Limitations of Existing LLMs
为了实现用户指令(user instructions)生成 AI 加速器的 HLS,一种直观方法讲用户指令与常用 HLS 模板平日对,作为 LLM 提示输入。这部分采用 skynet 中 HLS 实现作为模板。
评估 GPT-4 根据指令生成硬件能力,观察 LLM 经常生成无法综合、功能不正确代码,后续列举常见失败情况。
(os:iSmart3-SkyNet/iSmart3 为 2019 年 DAC-SDC 低功耗目标检测竞赛中 GPU 和 FPGA(Ultra96 FPGA 和 Pynq-Z1 FPGA)双料冠军。当年 Jetson tx2 取得 0.731 IoU 和 67.33 fps;在 Ultra96 FPGA 取得 0.716 IoU 和 25.05 fps。个人认为当年 TinyML 方向一味追求小模型,在岌岌可危保证精度同时极力追求速度,是一个不现实的想法。边缘设备算力总是随着时间增加,永无尽头卷指标是没有很多意义。TinyML 中甚至对部分指标已经到了几乎疯狂。剪枝、量化、蒸馏等方式最好的利用是在当今 MM-LLM 时代。)
Misinterpretation of variable definitions
实现硬件加速代码需要精确定义变量和函数以准确实例化模块,但 LLM 可能会实例化不正确大小模块,见图 2(a):
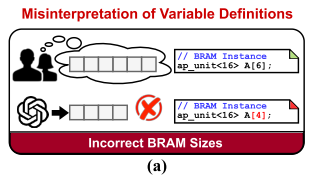
这个问题由于 LLM 难以理解指令中标识符和代码中变量联系,导致误解。
Inability to capture long dependencies
AI 加速器参数通常相互交织,一个模块一组参数容易受到另一组参数影响。导致长期依赖。当前 LLM 在处理长依赖关系经常出错,在后期模块设计生成忽略早期设计配置,见图 2(b):
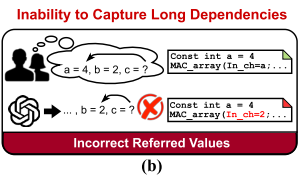
e.g. 前面 BRAM 大小影响分块计算大小,分块计算影响 PE 数量。当输入维度将并行指定为 4 时,LLM 在生成 MAC 阵列时候忽略这一点,仅考虑 2 个并行输入参数。
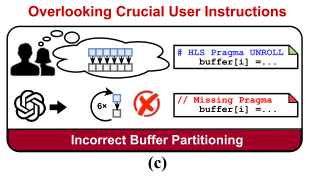
Overlooking crucial user instructions
LLM 难以推理两种关系:
这个问题跟上述长依赖性问题不同,这种限制涉及多个设计概念之间关系,而这些设计概念不一定由长代码分隔。
e.g. 某些数据维度上展开(并行化)计算需要沿着相同的维度对依赖数据的 BRAM 实例进行分区。然而,如图 2(c)所示,现有的 LLM 生成的代码往往将设计概念孤立地对待。此外,LLM 在将自然语言指令与适当的代码生成联系起来时可能会遇到困难,例如,当被指示模块化某些子模块时,它们可能无法识别相关的领域特定指令。
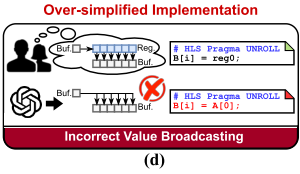
Over-simplified implementation
AI 加速器实现需要类如 HLS 编码风格来描述硬件,e.g. 将一个元素从一个缓冲区广播到另一个分区缓冲区的多个位置,避免在两个缓冲区内直接赋值。相反,需要首先将元素分配给类似寄存器变量,然后这个中间寄存器数据分配到另一个缓冲区的多个位置,防止源缓冲区内发生访问冲突。如图 2(d)所示,往往忽略硬件设计中细节,生成不切实际设计。
C. Closed-sourced LLMs vs. Finetuned Open-sourced LLMs
上述局限性表示 LLM 在理解硬件设计代码方面不足,潜在解决方案是使用带注释 HLS 代码对开源 LLM 进行微调。但由于缺乏高质量 HLS 代码以及设计描述和封闭源代码的高级 LLM,这个方法面临挑战。这些障碍建议采用来源但功能不够强大的 LLM,本小节研究功能强大闭源 LLM 和微调开源 LLM。
对 GPT-4 和 CodeGen 进行基准测试。
-
Task:在HLS中实现两个向量内积运算;
-
Metric:Pass@k,代表k次尝试中成功编译比例;
-
Prompt:“在HLS中实现两个向量之间的内积运算。你是AI加速器设计方面的专家,拥有广泛的HLS编码知识。” —— “Implement the inner product operator between two vectors in HLS. You are an expert in AI accelerator design with extensive HLS coding knowledge."
Finetuning strategy
两阶段微调策略:
-
从github上收集7000个开源HLS代码片段,使用masked prediction objective对CodeGen进行微调。
-
创建10个定制HLS模板及其说明,微调LLM和对应AI加速器设计。
Observations
见表 1:
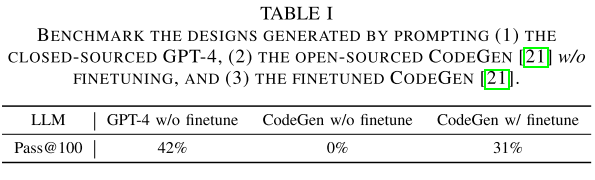
未微调之前 CodeGen 为 0% 正确率,微调后为 31%,但跟 GPT-4 对比还是有显著差距。
D. Capabilities of LLMs
先前工作表明 LLM 能够通过 STF 和 in-context 学习到丰富表示。
Generalization capability from in-context demonstrations.
见图 3:
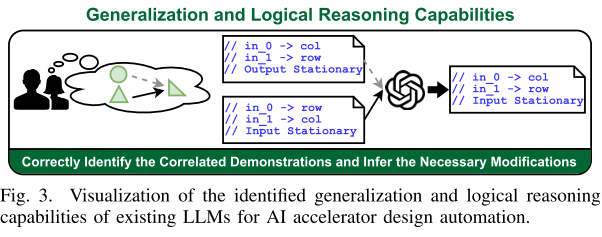
给定 HLS 演示两个片段,LLM 根据用户指令生成新的硬件风格。在保持相同编码风格和修改设计满足新的需求,推断演示设计差异。本文发现当提供与用户指令有一定关联高质量示例时,LLM 的上下文学习能力能够被激活。
Logical reasoning capability under multiple demonstrations
见图 3,LLM 可以对用户指令所需功能和演示中实现功能相似性进行逐步分析,选择一个适当动作为起点。表明 LLM 的逻辑推理能力,强调高质量演示重要性。
What We Can Learn: Insights From The Assessment
Decoupled hardware template design
-
适当设计硬件模板以在设计空间中解耦不同硬件功能,避免长依赖性;
-
将复杂问题分解成更简单子任务,即不同硬件功能独立。不同硬件功能独立渐进生成,而不是一次性生成所有冗长代码。
Prioritize in-context learning given limited data
由于注释数据稀缺性,无法以监督方式微调开源 LLM。利用封闭 LLM in-context 和 logical reasoning 是一个更有效选择。
Proper prompt engineering
In-context 学习关键在于目标领域高质量演示:
-
输入设计指令强相关性;
-
广泛涉及参数传达丰富领域知识,增强处理各种输入指令能力。
Instantiate The Drawn Insights: The Proposed GPT4AIGChip Framework
A. The Overall Pipeline of GPT4AIGChip
GPT4AIGChip 在 GPT-4 基础上实施 in-context 学习,并整合两个关键组件:
-
LLM 友好的硬件模板,将复杂 AI 加速器代码简化为模块结构;
-
增强演示的提示生成器(the demo-augmented prompt generator),在提示中添加演示来增强 LLM 生成优化 AI 加速器能力。
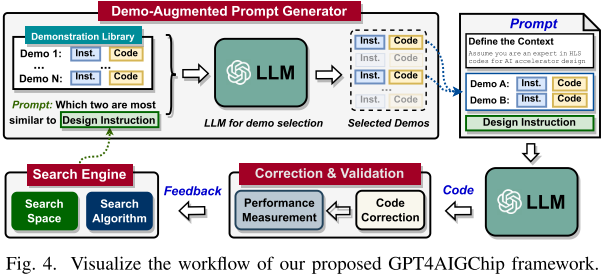
通过组合,然后 GPT4AIGChip 采取迭代方法改进生成 AI 加速器涉及,逐步接近最优。见图 4:
-
搜索引擎根据以往搜索设计反馈,识别下一个设计以及对应指令,指导 LLM 友好硬件模板实现和评估;
-
demo-augmented prompt generator 为每个模板创建一个提示,结合相关演示(instruction-
code pairs)增强 LLM 上下文学习;
-
配备上述提示的 LLMs 依次生成硬件设计实现;
-
设计验证流程检查 LLMs 生成的代码,执行必要的修改以确保其可部署性。
B. The LLM-friendly Hardware Template Design
The desired template design principles
三个设计模块关键原则:
-
高模块化(High modularity):由于 LLM token 数量有限,上下文学习使用输入样本代码大小和每轮生成代码大小受到严格现实。高模块化设计生成方法可以大幅减小 LLM 输入和输出所需代码大小。
-
解耦模块设计(Decoupled module design):将代码模块分割成更小模块无意中引入配置设置之间的耦合和依赖。提出了独立的模块生成,每个模块保持其本地设置。然而,这可能导致总体设计次优,连接模块之间的数据速率不匹配可能导致停滞或死锁。为了协调模块操作,建议增加一个搜索引擎和可调整的模块间通信方案。这些方案可以最佳地协调所有本地设置,调节通信速率和带宽差异。因此,LLM 可以基于其本地设置生成每个模块,维护解耦原则。
-
深层设计层次结构逐步生成设计(Deep design hierarchies for step-by-step design generation):模板采用了基于层次的、模块化的生成方法,简化了过程,并在每个阶段减少了复杂性。每个模块由多个子模块组成,这些子模块遵循解耦原则,并可能进一步包含自己的子模块。这种递归嵌套持续到进一步划分变得不可行(见图 5(b)中的 Level-L)。这允许 LLM 系统地为每个模块生成设计层次结构,在每个步骤中限制代码大小和复杂性。
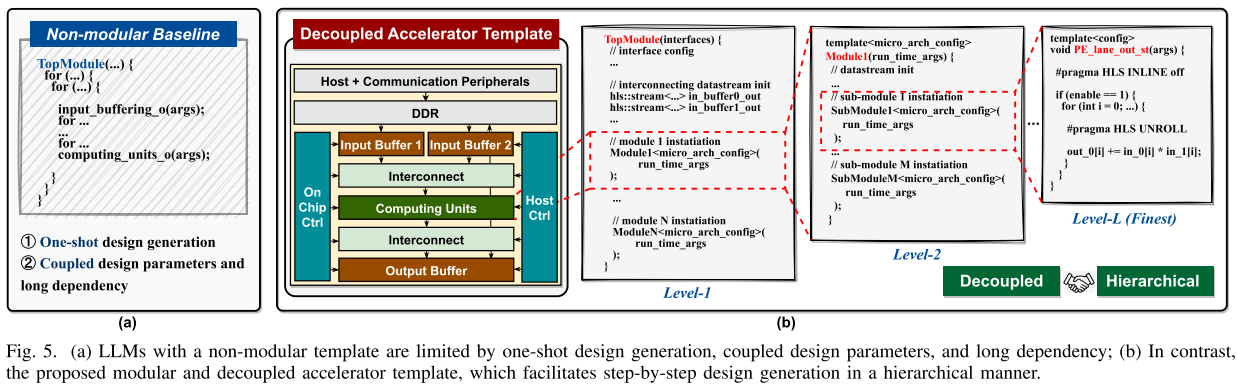
Overview of the proposed accelerator template
在三个关键原则基础上,引入一个新的、模块化的、解耦的加速器微架构及相应的代码模板,如图 5(b)所示。
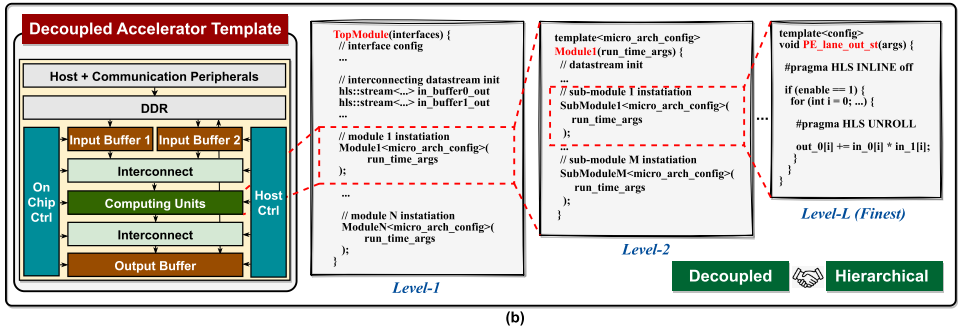
这里关注于广泛使用的 GEMM 操作符,但考虑在 AI 算法中广泛应用,模板保留一个通用结构。模板由一系列多功能模块组成,每个模块都可以根据提示和本地配置设置灵活重新设计,提供不同的硬件效率甚至独特的功能。
每个模块都由嵌套的子模块层次结构组成,以便于 LLM 逐步生成。模块通过基于流的通信链接和异步数据 FIFOs 相互连接,以减少不同模块之间数据生产和消费速率可能出现的不匹配的控制开销。每个模块内的处理开始和结束主要取决于数据的可用性,促进细粒度的操作重叠和简化控制开销。对于具有多个输入端口的模块,例如图 5(b)中的互连模块,我们还包括了额外的同步逻辑以确保数据对齐和准确性。
Key components of the proposed accelerator template
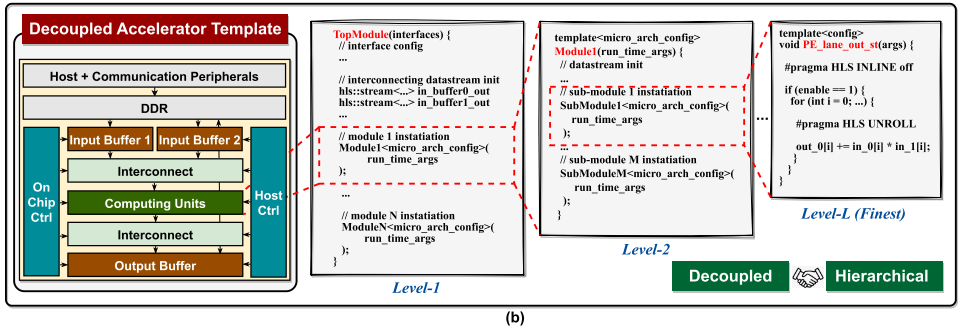
-
Buffer modules:
缓冲模块,方便后续计算单元并行数据访问。
-
Computing units modules:
计算单元模块,主要用于处理计算,e.g. 乘法和加法。互连被实现为 MAC(乘积累加运算)单元集合以平衡空间数据重用、MAC 数据传播延迟和片上缓冲带宽竞争。为更容易的 LLM 辅助生成结构化嵌套设计层次,以适应多种 MAC 互连风格。e.g. 单个 MAC 可以连接以创建一个一维 PE(处理元素)通道子模块,而多个 PE 通道可以互联以形成一个更大的二维 PE 阵列模块,增强可扩展性。
-
Interconnect modules:
它们被设计用来灵活地在缓冲模块和计算单元模块之间分配和同步数据。
-
Control (Ctrl) modules:
它们负责从主机获取初始控制数据、解码控制数据,以及可能在运行时生成控制数据以改变各种模块的工作模式。
-
Flexible communication arbitrators:
管理互连模块之间可能存在的数据生产/消耗速率和带宽的不匹配,从而实现速率和带宽的转换。
Implication and advantages of the proposed template
-
减少代码大小和模块解耦设计;
-
利用额外的数据集进行微调:
-
跨领域适用性。
C. The Demo-Augmented Prompt Generator Design
Workflow
LLM 在识别不同指令之间相似性能力,并应用到演示增强提示中,减少人类知识在 AI 加速器设计中需求。如图 4 所示:
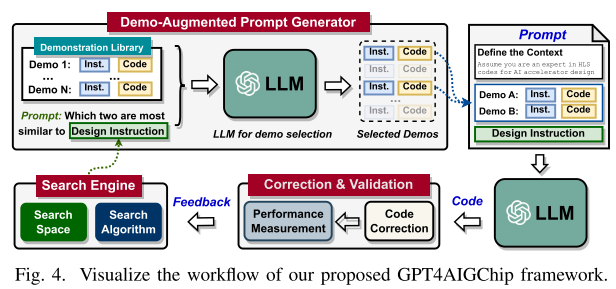
在每一次迭代中,给定搜索引擎生成的设计指令,使用 LLMs 来识别生成的设计指令与演示库中指令之间的相似性。然后选择两个最相似的指令,并将它们与其对应的实现配对,作为本次代码生成的演示。
Demonstration library
演示库是增强式演示提示生成器中至关重要的组成部分。目标是构建一个演示库,涵盖目标领域(本文中为 GEMM)的多样化设计选择。这确保了演示库提供了丰富的领域知识,能够满足搜索引擎生成的多样化设计指令的需求。指导原则:
-
高度相关的指令和代码对(Highly correlated instruction and code pairs):
每个演示包括详细的实施指导和相应的代码,配有注释。每条指令明确链接到特定的代码段,提供了它们之间关联和理念的清晰性。
-
多样化的设计选择(Diverse design choices):
为了确保 LLMs 在给定的设计指令中找到具有足够领域知识的演示,生成了分开的演示,展示了搜索空间中每个设计参数的修改。
D. Implementation of Other Components in GPT4AIGChip
Hardware design space
设计了 5 个硬件设计参数:
-
MAC array sizes:
指示实例化加速器中 MAC 阵列中 MAC 总数的大小。
-
Network-on-Chip (NoC) styles:
确定数据从计算单元到和从计算单元之间的分布,以及数据在它们之间的传播方式。
-
On-chip buffer sizes:
指示加速器设计中三个主要缓冲区的容量,包括两个输入缓冲区和一个(部分)输出缓冲区。
-
On-chip buffer partition styles:
确定在每个缓冲区内部的片上存储块之间的数据分配。
-
Data reuse patterns:
定义了缓冲后如何在计算过程中重用数据。
The adopted search algorithm
GPT4AIGChip 加速搜索进化算法,都是初始化 --> 优秀选择 --> 变异和交叉 --> 更新种群 --> 优化器解选择 等常规操作,不过多阐述。
Design validation and code correction flow
设计验证和代码修正流程:
-
Synthesizability Evaluation(综合性验证):
- 利用标准化的 Vivado HLS 工具对 LLM 生成的代码进行综合化评估;
- 通过自定义的错误解析器处理输出日志消息;
- 如果解析器发现超出其能力范围的错误,可能需要进行以下操作之一:(1) LLM 驱动的设计重新生成,或者 (2) 人工干预进行错误修正。
-
Correctness Verification(正确性验证):
- 确保设计在功能上能够产生预期的结果。构建了一个测试台架模板,包括预期的输入和输出;
- 将生成的输出与预期输出进行对比,以确认准确性;
- 鉴于可能出现的各种错误,这一步骤不包括自动修正。如果结果不正确,则需要重新生成设计。
-
Performance Analysis(性能分析):
- 评估性能指标(例如延迟)和资源使用情况,以向搜索引擎提供反馈;
- 使用 Vivado HLS 内置工具在设计综合后生成这些性能和资源估算。
Experimental Evaluation
A. Experiment Setup
设计流程选择 Vivado HLS 设计流程,使用 XCZU7EV MPSoC 的 ZCU104 FPGA 作为验证。环境部署在 PYNQ 中,在开发板上展示最终性能评估和测试。
B. Benchmark with Manual and Automated Designs
与两种基准进行比较:
-
CHaiDNN 的硬件设计:这是一个行业级设计自动化工具提供的硬件设计。
-
人工优化设计:硬件设计师根据模板参数和需求进行调整和微调。(大约一天)
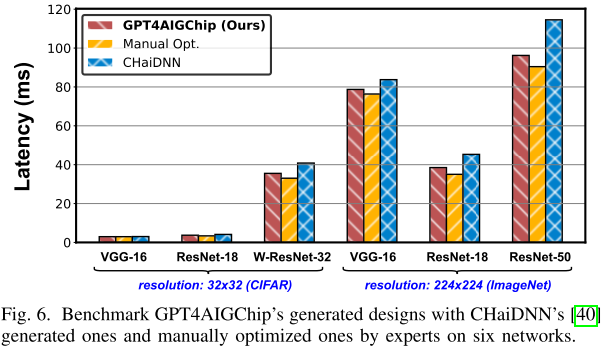
图 6 所示,文中以 6 种不同网络和 2 种不同输入分辨率为基础评估加速效率:
-
延迟减少了 2.0% 〜 16.0%,表明 GPT 4AICchip 已经成功地并实际地展示了第一个 LLM 支持的 AI 加速器设计自动化框架;
-
硬件效率上能够与人工专家手动优化设计相匹配,同时大幅降低了人力成本。
C. Effectiveness of the Search Scheme
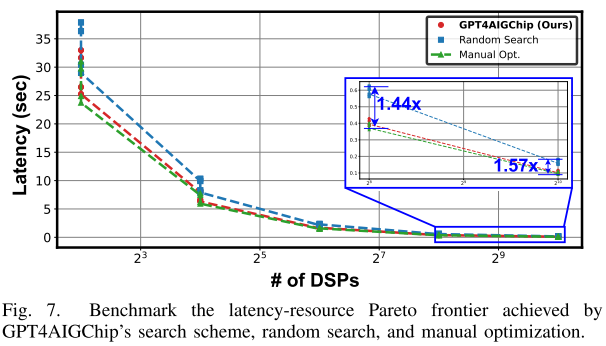
在 Resnet-50 上输入 224x224 图片,与随机搜索人类专家手动优化加速器比较,并可视化 Pareto 前沿,即延迟和使用的 DSP 资源之间的权衡。(os:这里随机搜索意思应该是在设计空间中随机选择参数,通常用作基准比较)见图 7:
-
随机搜索生成的设计在相对丰富的 DSP 资源设置下表现不如人工专家手动优化设计的延迟-资源权衡。
-
GPT4AIGChip 框架能够优于随机搜索基准,并能够与人工专家手动优化设计相匹配,在相似的资源条件下达到相似的硬件效率。
D. Ablation Study of the Prompt Generator
提示生成消融实验
以 Stationary Computing Units 为生成目标,使用 Pass@10 作为评估指标。
Prompt format and explicitness
提示格式和明确性。首先验证使用演示增强提示符必要性,考虑两种替代提示设计:
-
No Demo: 使用相同设计指令,但没有演示指令和代码;
-
High-level Description:将演示中显式指令替换为高级描述(e.g. 输出静态计算单元)
见表 2:

演示增强提示将 LLM AI 加速器设计能力提高 50% 和 30%,对比 No Demo 和 High-level Description。
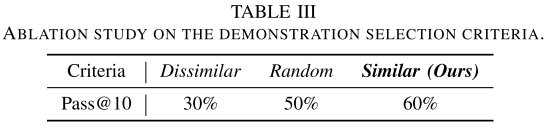
Demonstration selection
除了选择最相似演示之外,还考虑随机选择(Random)和最不相关选择(Dissimilar),见表 3:
The number of demonstrations
评估提示中演示数量关系,见表 5:

E. Visualizing the Generated Designs
更好说明上下文演示生成设计过程,图 8 给出示例:

基于内积/外积的矩阵乘法的说明和演示。
Limitations And Future Work
主要为对演示库依赖、依然需要人类参与需求和生成加速器验证成本。

