IncreMacro: Incremental Macro Placement Refinement
此篇文章来自林亦波和余备 publish 在 ispd 2024 上论文,提出一种增量宏单元布局优化算法,提高布局可布线性(布线拥塞 routing congestion)和时序性能。对布线性能算是开了一个新的课题,非常具有研究意义。
文章获得 ispd 2024 best paper 提名,遗憾的是最后 best paper 由任昊星团队的 《Novel Transformer Model Based Clustering Method for Standard Cell Design Automation》摘得殊荣。
Introduction
在宏单元布局中,经验丰富工程师会通常将宏布局放置在芯片外围区域,以避免中心区域宏单元拥塞。现有分析布局方法(DREAMPlace,RePlace,ePlace,NTUPlace)布局过程中优先优化布线长度,这种方法容易导致布局中心拥塞,对标准单元布局产生负面影响。见图一:
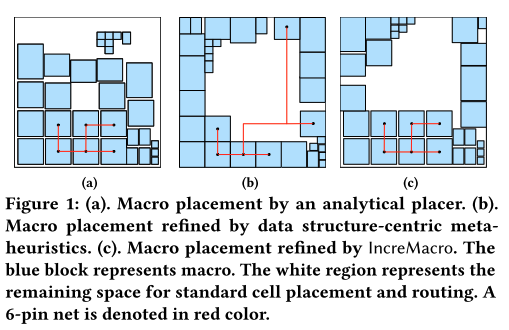
-
图1a为一个分析型布局,其中宏被放置在核心区域,导致宏拥塞。宏拥塞导致将剩余标准单元布局空间分割成不同子区域,导致标准单元布局增加布线长度等。
-
图1b为基于数据结构等元启发方法对分析型布局进行合法化例子。此方法虽然成功消除宏单元重叠而且将宏单元移动至芯片外围,但扰乱布局中宏单元相对位置关系,导致布线长度增加。
-
图1c为IncreMacro实现的理想宏单元布局方法。保证布线优化同时消除核心区域宏单元拥塞。
总结:
-
本文提出 IncreMacro,通过最先进的分析性布局算法逐步优化宏布局。
-
提出一种新的算法流程,包括 KD-tree-based macro diagnosis(基于 kd 树的宏单元诊断),**gradient-based macro shift(基于梯度的宏块移动)**以及 constraint-graph-based linear programming for macro legalization(基于约束图的线性规划进行宏块合法化)。保证布线优化效果同时,消除布局中心宏单元拥塞。
-
文章在多个 7nm 工艺节点的 risc-v 电路实验,
- IncreMacro 集成到 DREAMPlace 中,布线后到 WNS 和 TNS 分别提高了 59.9% 和 63.9%,布线长度和总功耗分别减少了 6.5% 和 3.3%;
- IncreMacro 集成到 AutoDMP 中,布线后到 WNS 和 TNS 分别提高了 99.6% 和 99.9%,布线长度和总功耗分别减少了 16.8% 和 4.9%;
Problem Formulation
见图 2:
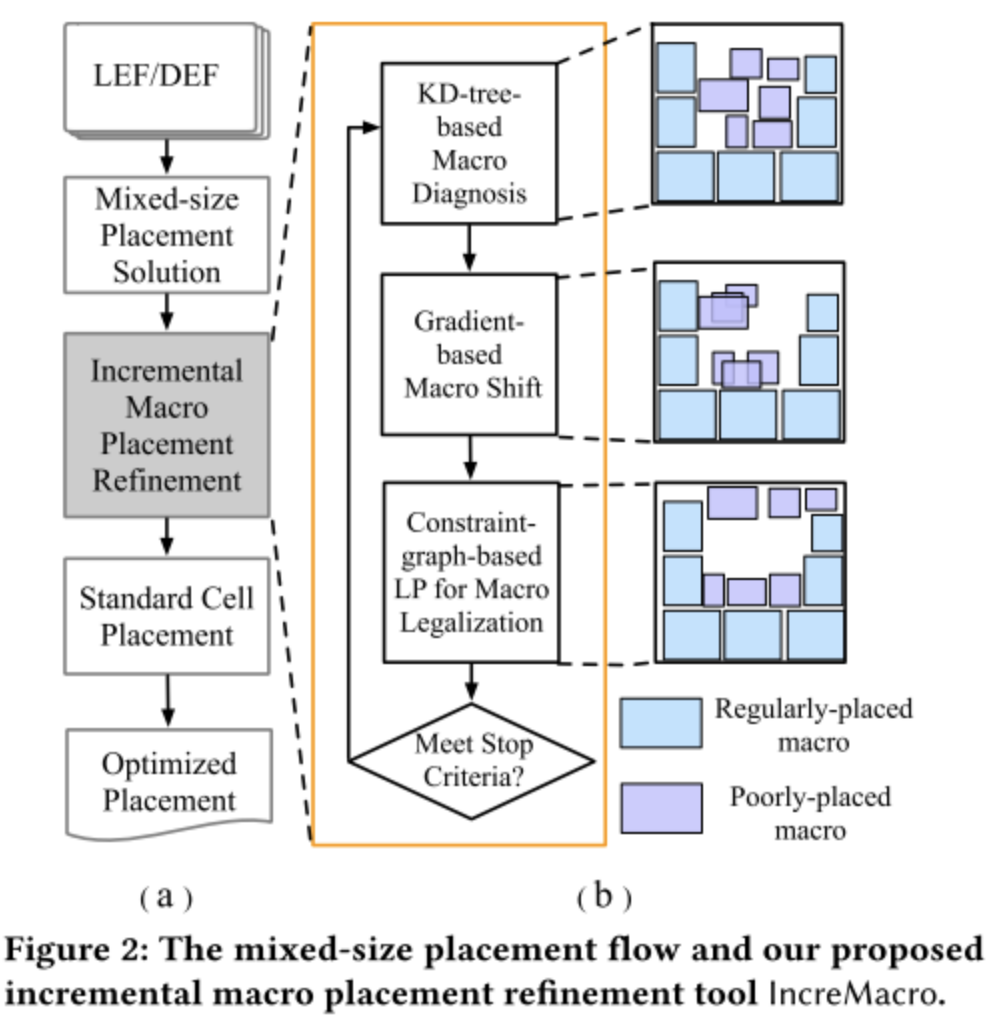
-
图 2a 展示 IncreMacro 布局流程,首先将包含 lef 和 def 电路文件输入分析布局器,生成一个包含合法化宏单元的混合布局原型,其次使用 IncreMacro 以迭代和增量的方式优化宏单元布局。完成后再使用分析布局器完成标准单元布局。
Macro Regularity Define
宏单元规则性定义,有可能引发拥塞的宏单元称为 “非规则放置宏单元” - “poorly-placed macros”,与之对应的成为“规则放置宏单元” - “regularly-placed macros”,见图 3:
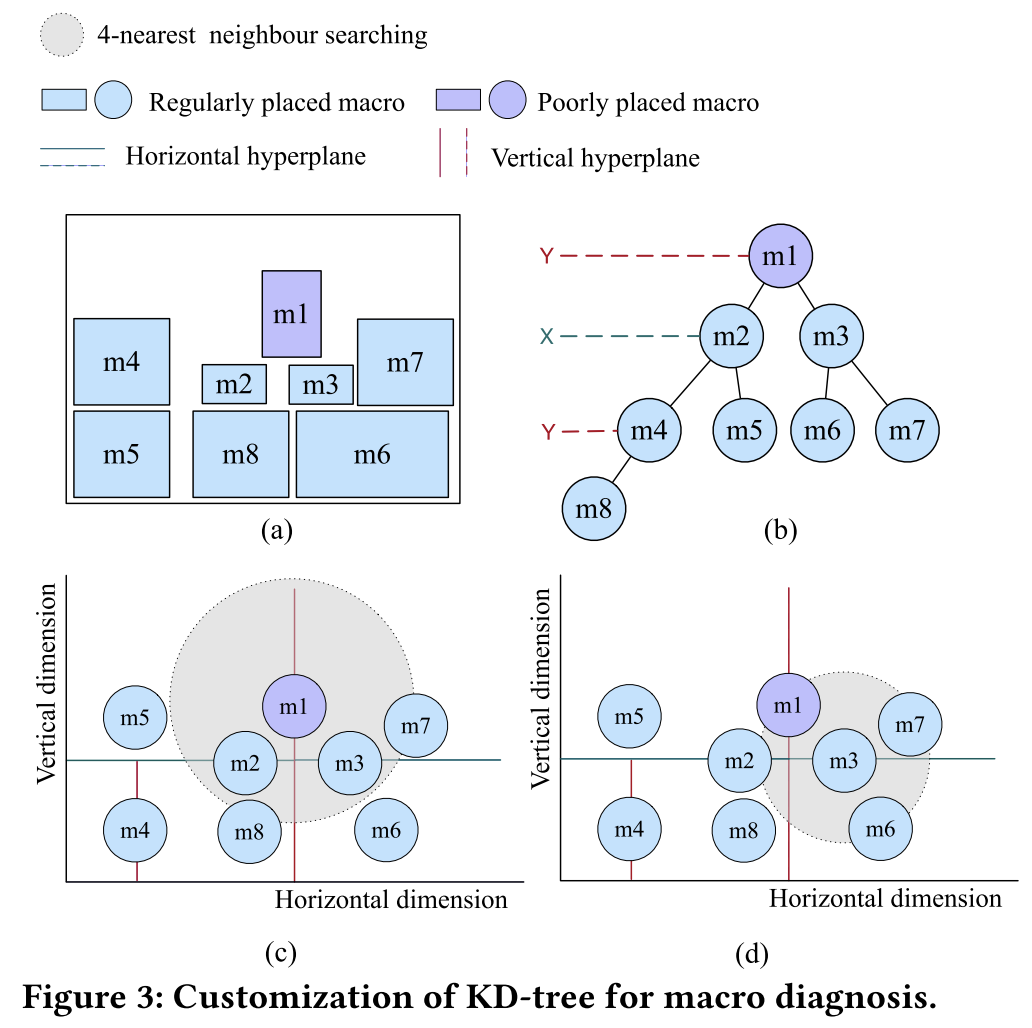
-
判断 regularly-placed macros 满足以下两个标准之一,第一个是与芯片外围边界相邻(
),第二个是与其他宏单元有规律排列( )
Define1(规则放置的宏单元):
给定一个宏单元
Define2(非规则放置的宏单元):
如果一个
Define3(宏单元诊断):
给定一个宏单元
Problem1(宏布局优化):
找到
Algorithm
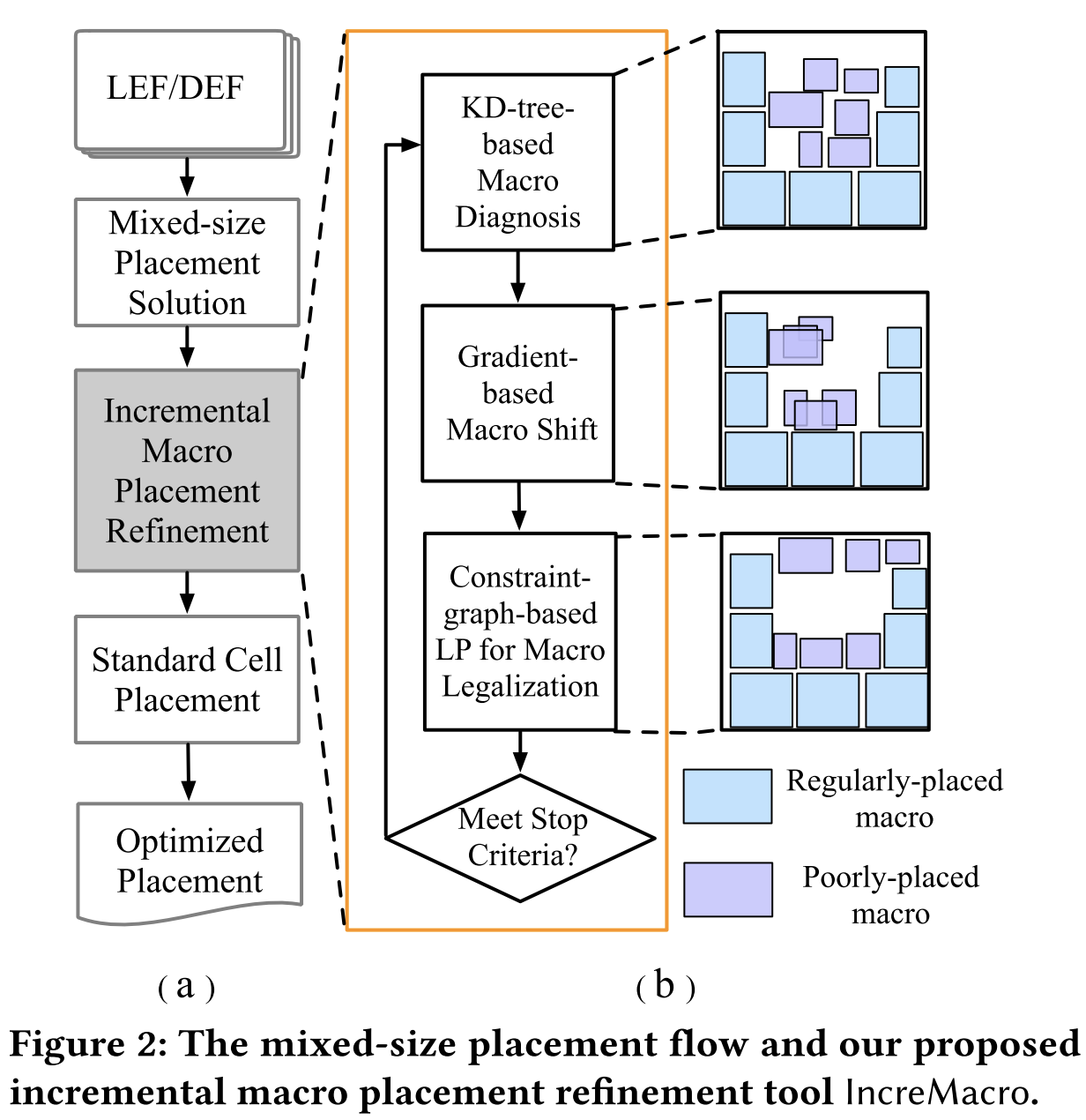
kd 树将宏单元分成规则和不规则两种 --> 使用梯度方法迭代移动不规则放置宏单元,以最小化线长为损失函数 --> 使用基于约束图线性规划方法消除宏单元之间重叠,最小化宏单元位移,进一步将不良宏单元推向芯片布局外围,同时保留初使宏布局相对位置关系。
KD-Tree-based Macro Diagnosis (基于 kd 树宏单元诊断)
kd 树是二叉搜索树的扩展,在 k 维空间进行排序,范围搜索和邻近搜索。kd 树中每个 node 代表一个 k 维点,非叶子节点通过生产分割超平面来均匀划分空间。kd 树支持最近邻搜索-nms,时间复杂度为
见图 3:
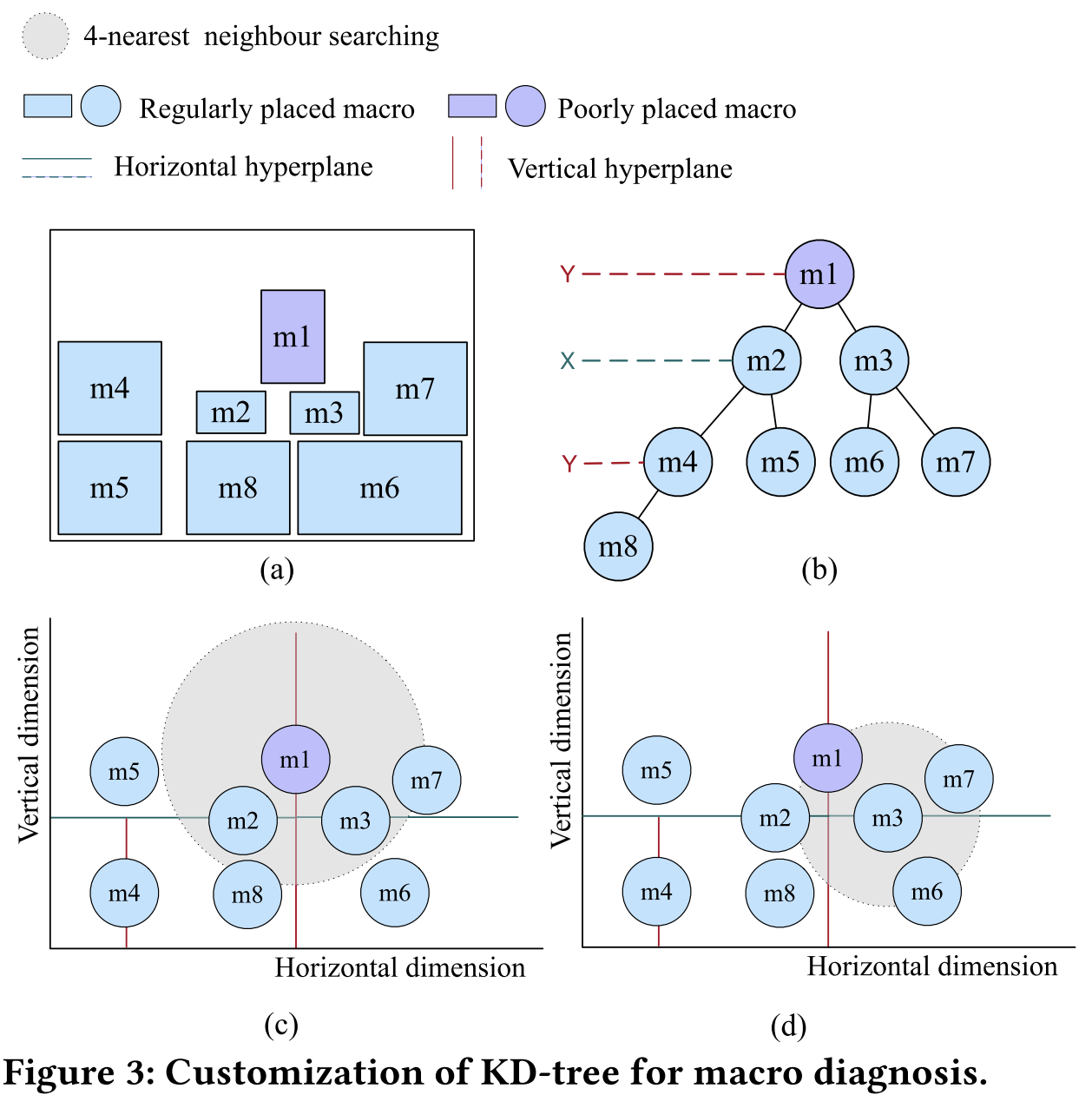
图 3a 中展示一个包含 8 个宏单元布局,图 3b 中构建一个 kd 树,图 3c 和图 3d 表示根据定义得出
Gradient-based Macro Shift
类似 dl 中神经网络训练过程,将每个位置不佳宏单元
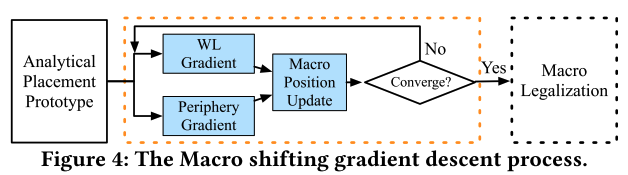
损失函数
-
外围成本
用于衡量宏单元偏离芯片边界程度。用于鼓励宏单元靠近芯片外围,离外围越近,外围成本越小。
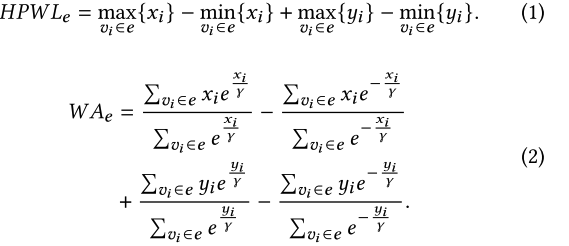
这个跟 DREAMPlace 一样
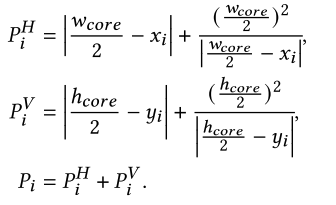
一个水平成本,一个垂直成本,
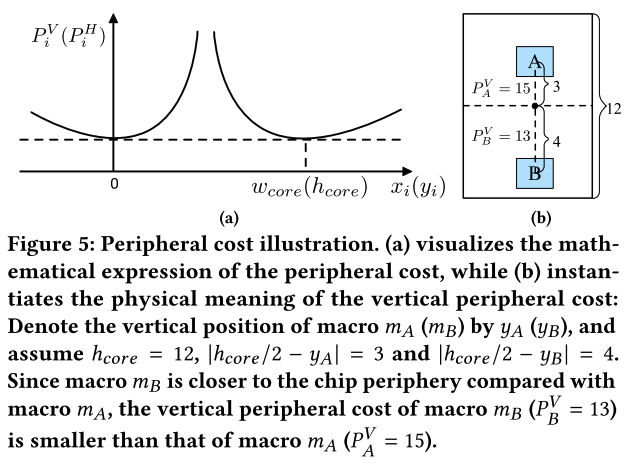
图 5 描述了这个例子,
Macro Legalization
使用约束图线性规划方法避免宏单元重叠
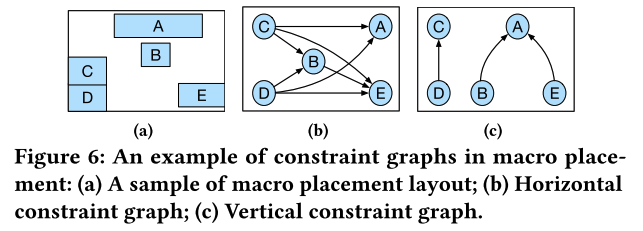
约束图定义
宏布局中约束图(constraint graph)是一个有向无环图(DAG),其中每个顶点代表一个宏单元,每个边表示宏单元之间相对位置关系。
创建两个约束图,水平方向
每一对宏单元相对位置关系必须在水平或者垂直方向指定,不可能同时出现在两个图中。
宏单元布局合法化改进
现有方法(eg. XDP)使用线性规划消除宏单元重叠,但在消除重叠时,可能需要调整某些边的方向,导致宏块相对位置关系被破坏,从而影响线长优化。
本文在分析器生成合法宏单元布局基础上构建约束图,同时保留宏单元的相对位置关系。比如一对宏单元
线性规划公式及目标
-
每个宏单元在合法化前后中心位置分别用
和 $(x’{i},y’{i}) w_{i},h_{i}$表示。 -
线性规划的目标是最小化宏块的位移量,从而尽可能保持原有的线长优化。
-
公式中引入辅助变量
,将位移目标转化为辅助变量总和。目标函数还包括次级目标,将宏单元推向芯片边界。
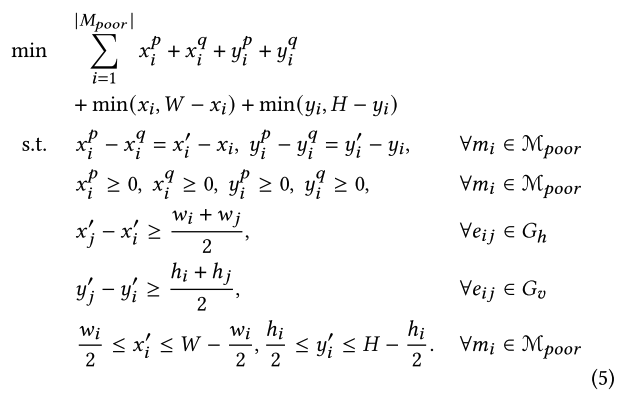
Experiments
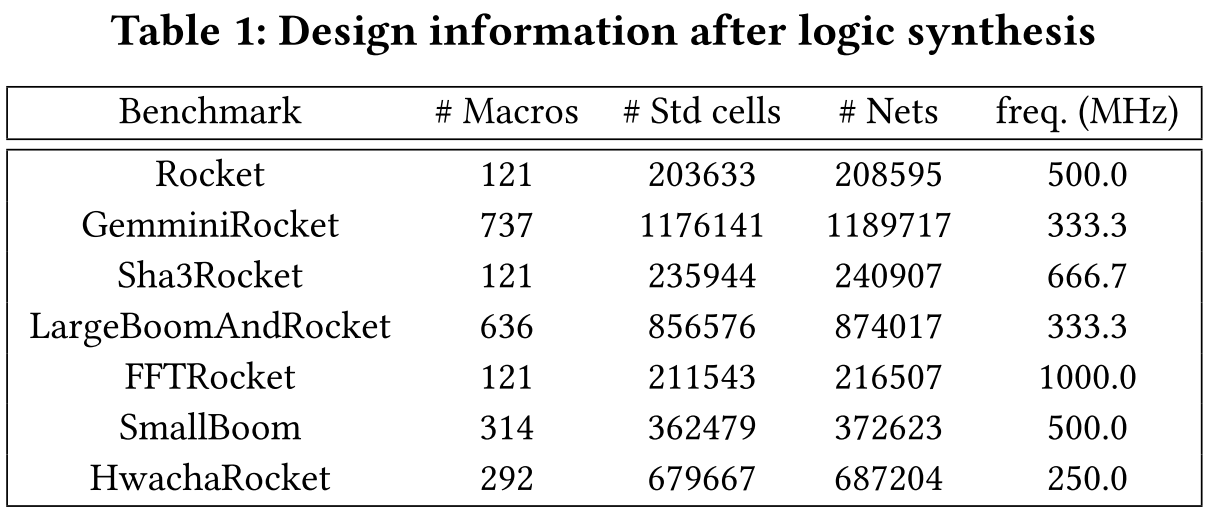
使用来自 chipyard 的 risc-v soc rtl 设计作为数据,其中 chipyard 为一个开源的 soc 开发框架,所有设计均是 risc-v soc 不同变体,核心是 rocket 和 boom。
-
Homepage: https://chipyard.readthedocs.io
为了将 rtl 设计转化为门级网表,使用 barstools 将 rtl 中存储模块映射到 sram,然后采用一个学术届 7nm 工艺节点 asap7,使用 cadence genus 进行逻辑综合生成门级网表,图一所示:
Experiment Setting
将 IncreMacro 集成到 DREAMPlace 和 AutoDMP 中
DREAMPLace/AutoDMP 宏单元布局 --> IncreMacro 宏单元优化布局 --> DREAMPlace 标准单元布局 --> Cadence Innovus 进行时钟树(CTS)综合、信号布线和 PPA 评测。
其中 DREAMPLace 和 AutoDMP 原始布局为 baseline
Overall Comparisons
关注指标为
-
线长 wirelength --> WL
-
时序 WNS (worst negative slack 最差的负时序),TNS (total negative slack 总的负时序时间之和,即小于 0 的 slack 之和)
-
功耗 Power
AutoDMP 无法完成 Sha3Rocket、LargeBoomAndRocket 和 SmallBoom 布局流程,见表 2 和表 3
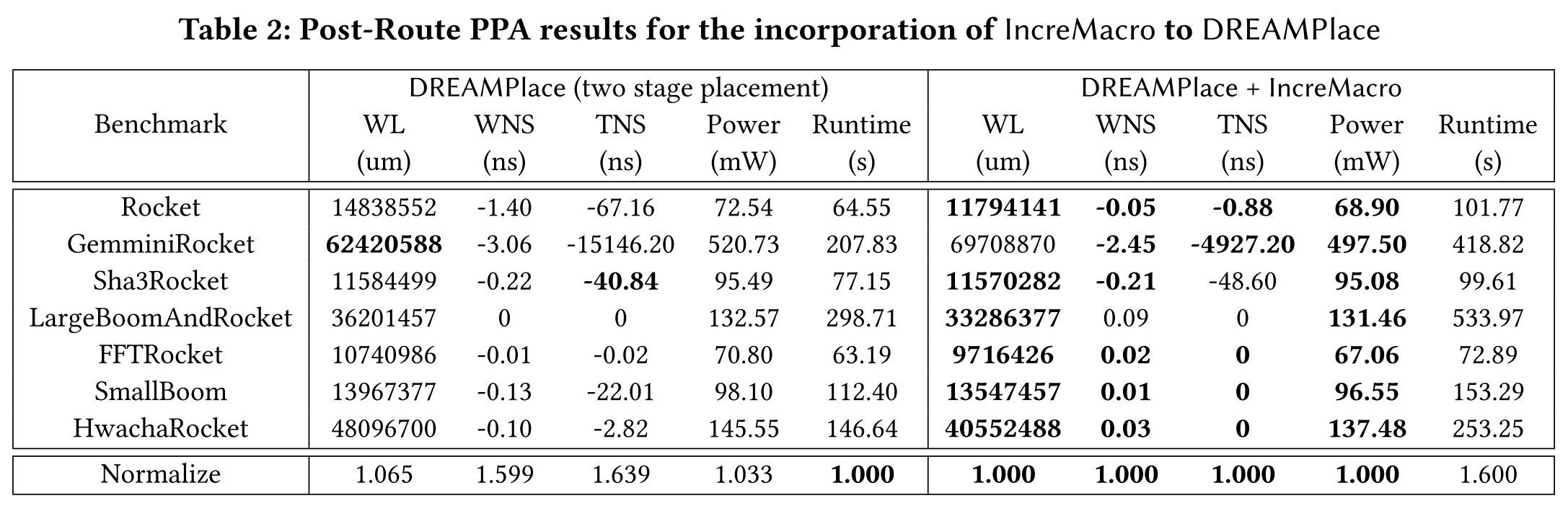
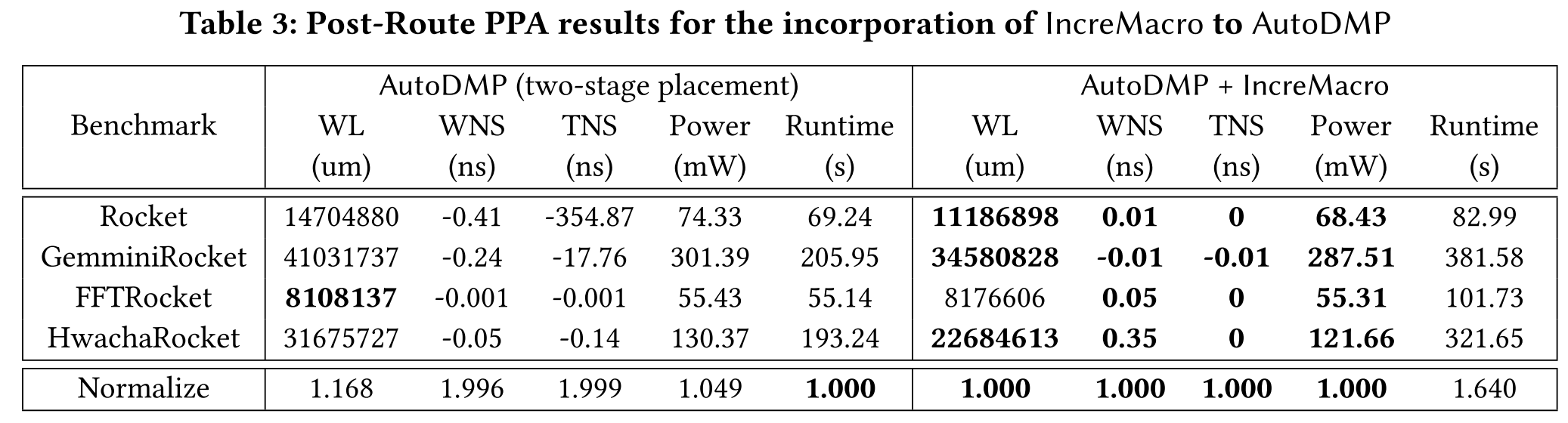
-
表 2 和表 3 展示了将 IncreMacro 集成到 DREAMPlace 和 AutoDMP 布局流程中的显著时序改进。布线后的线长分别减少了 6.5% 和 16.8%。
-
对于 DREAMPlace,设定违约裕量(WNS)和总违约时间(TNS)分别改善了 59.9% 和 63.9%;
-
对于 AutoDMP,分别改善了 99.6% 和 99.9%。
-
此外,集成 IncreMacro 还分别减少了 DREAMPlace 和 AutoDMP 布线后的功耗,分别减少了 3.3% 和 4.9%。
Analysis, Visualization, and Profiling
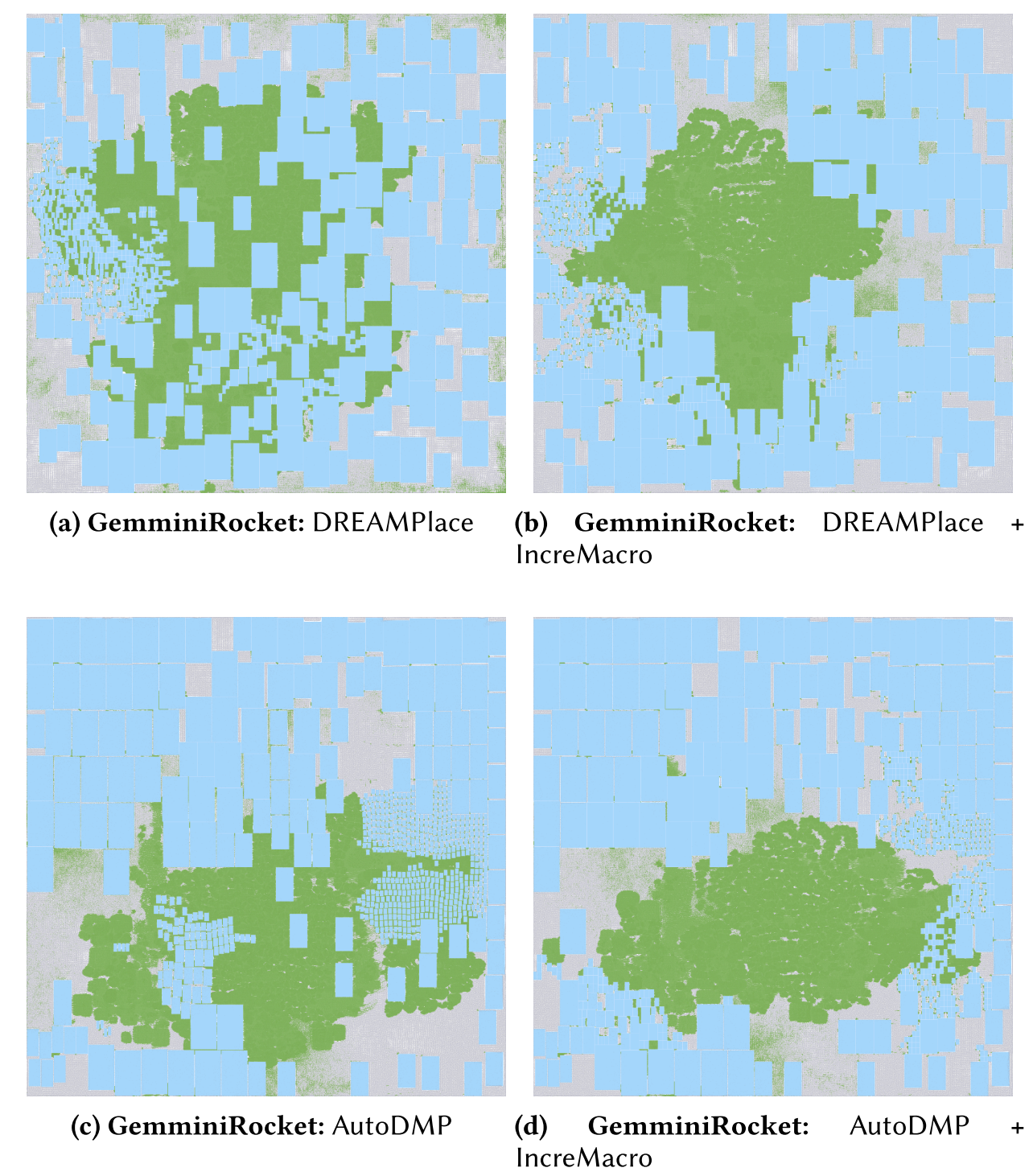
图 7 可视化展示了 GemminiRocket 在 DREAMPlace 和 AutoDMP 上布线后的布局,分别是在集成 IncreMacro 之前和之后的情况:通过比较 DREAMPlace(图 7(a))和 AutoDMP(图 7©)的宏布局,AutoDMP 显示出更优越的性能,宏阻塞减少,导致可布线性和时序性能的提升。
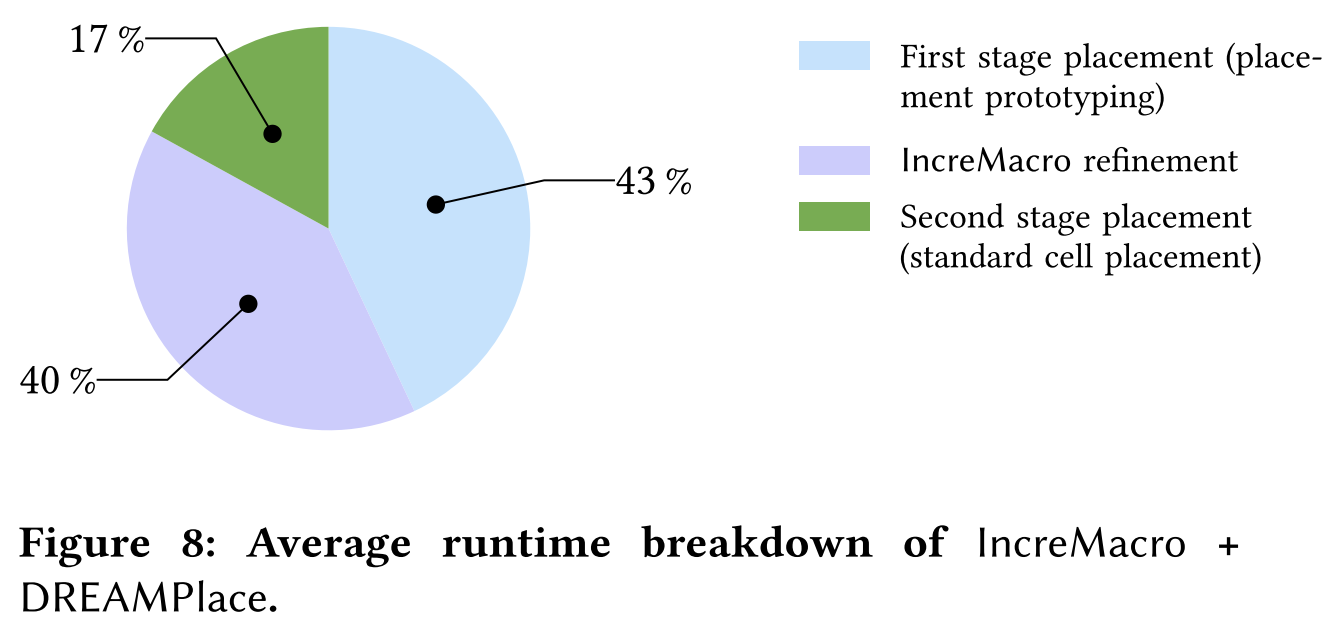
图 8 展示了 DREAMPlace + IncreMacro 在表 2 中 7 个基准测试上的平均运行时间分布。DREAMPlace 的第一阶段布局(混合尺寸布局原型)占总运行时间的最大比例(43%),而 IncreMacro 占总运行时间的 40%。

